Les secrets de l'algorithme SEO de Google révélés ? Que disent les documents du Google Leak

Ce qu'il faut retenir
EN RÉSUMÉ
Avec le Google Algo Leak, certaines intuitions historiques des SEO trouvent des éléments de confirmation. Les documents fuités ne dévoilent pas la formule de classement de Google, mais révèlent des milliers de modules et signaux liés au crawl, aux liens, aux clics, à l’autorité, à la topicalité, aux titres ou encore aux comportements utilisateurs. Le contenu insiste surtout sur les implications stratégiques : travailler la cohérence sémantique, l’expérience utilisateur, les balises title, l’autorité des auteurs, la qualité des liens et la fraîcheur des contenus. Le leak ne remplace pas l’analyse SEO, mais affine la compréhension du fonctionnement de Google.
Le Google Algo Leak confirme plusieurs intuitions SEO : topicalité, clics, autorité, fraîcheur et signaux utilisateurs comptent bien.
La fuite révèle des modules internes comme NavBoost, Glue, siteAuthority, titlematchScore ou encore des mécanismes de demotion.
Google semble évaluer la pertinence à plusieurs niveaux : page, domaine, auteur, liens, comportement utilisateur et cohérence thématique.
Le leak ne donne pas de formule magique, mais renforce l’importance d’un SEO fondé sur qualité, UX, autorité et structure.
1h de coaching avec un expert
Réserver mon coaching
DÉBUT DE L'ARTICLE
Des années que cela n’était pas arrivé, ou en tout cas, dans des proportions infimes. Pendant des mois, certains ont relu les transcriptions des auditions de certains Googlers (employés de Google) par le ministère Américain de la justice pendant lesquelles Google devait expliquer le fonctionnement de son algorithme. Plus de deux décennies pendant lesquelles certains SEO ont scruté les brevets déposés par Google afin de comprendre plus précisément comment l’algorithme du moteur de recherche fonctionnait.
Toute ces années et ces efforts, qui ne sont pas à négliger, ont permis d’infirmer, de confirmer, d’affiner une certaine compréhension de Google.
Mais ça, c’était jusqu’au 05 Mai 2024…
L’histoire du leak de l’algorithme de Google
Le dimanche 05 Mai 2024, le célèbre Rand Fishkin qui s’est éloigné du SEO depuis déjà 6 ans (même s’il reste un excellent praticien reconnaissons-le), reçoit un email d’un expéditeur inconnu lui donnant accès à des documents internes de la division Google Search, et plus particulièrement de la Content Warehouse API (c’est à dire là où est “stocké” le code et la documentation du code des APIs).
Après plusieurs échanges avec cette source anonyme ainsi qu’avec d’autres ex-Googlers afin d’authentifier la véracité de cette fuite de données, Rand a partagé le 24 Mai la documentation obtenue avec Mike King, le fondateur de iPullRank qui nous a honorés hier des premières informations sur la fuite d’informations sur l’algorithme de Google.
Je dois reconnaître que c’est massif.
C’est massif, et ça en dit long aussi sur les relations entre Google et les professionnels du référencement naturel.
Cela en dit long car nous découvrons des confirmations mais aussi parfois des “mensonges” que Google a publiquement diffusé ces dernières années auprès de professionnels. Avec ce leak du moteur de recherche #1 en France, la confiance entre les professionnels du SEO et Google va certainement s’amenuiser encore un peu plus.
Quand cela fait plus de 10 ans que vous êtes dans le SEO comme moi, ces mensonges vous n’y croyiez pas, en tout cas pas à tous. Tout simplement car vous avez acquis une compréhension du fonctionnement de l’algorithme qui vous permet rapidement d’identifier le vrai du faux. Mais il est vrai que pour toute une génération de nouveaux SEO qui ont été biberonnés par les Google Search Liaison Agents, les porte-paroles de la firme de Mountain View, ce leak peut avoir d’importantes conséquences.
Cet article en est déjà à sa troisième version.
Ce que je vais vous partager ci-dessous découle en partie du travail de Mike King, fondateur de iPullRank aux États-Unis, de Rand Fishkin ancien de Moz, et Andrew Ansley de HeliumSEO.
A leur travail, j’ajoute le mien. Entre la première version de cet article et celle que vous lisez maintenant, j’ai passé plusieurs jours à décortiquer les contenus et les fichiers du leak.
J’ai décortiqué une partie de ces fichiers que vous pouvez retrouver ici. Vous noterez en haut à gauche qu’il existe plusieurs versions. La v0.5.0 est la version corrigée sans le leak, il faut vous reporter aux versions entre 0.2 et 0.4. La 0.4 semblant être la plus complète.
Peut-être que pour vous comme pour moi, vous ressentirez une certaine émotion à les décortiquer. Le sentiment d’avoir “toujours su” et de trouver des éléments probants qui semblent confirmer votre intuition.
Maintenant que le moment émotion est passé, allons-y.
Mais de quelle quantité de documents parle-t-on ? 14 014 features en 2 596 modules !
Dans la documentation récupérée, on peut identifier 2596 modules qui intègrent 14 014 fonctionnalités / caractéristiques / signaux qui sont impliqués dans plusieurs briques du SEO telles que le crawl, Youtube search, les liens, etc.
La documentation présente ainsi chaque module de l’API découpée en :
- Summary ;
- Types ;
- Functions ;
- Attributes.
Ces modules sont ensuite sollicités les uns après les autres par l’algorithme de classement de Google afin de créer la SERP (Search Engine Result Page). Néanmoins, nous n’avons pas accès aux documents complémentaires afin de vraiment creuser le fonctionnement de ces modules les uns avec les autres et leur éventuelle pondération qui est sans doute dynamique.
Ainsi, le travail réalisé consiste à lire des centaines de pages qui ressemblent à ce que l’on retrouve ci-dessous et de comprendre les relations des attributs présents sur ces pages par rapport aux autres afin de vraiment identifier ce qui se cache sous le capot.


Ce qu’il faut espérer et ne pas espérer lire dans cet article
Tout d’abord, ne vous attendez pas à trouver la formule magique pour vous positionner en première position sur Google. Les documents qui ont fuité n’offrent qu’une vue parcellaire du fonctionnement de ces différents signaux ensemble.
Je parle bien de signaux car la liste de modules et de features ne correspond pas uniquement à des critères de classement, autrement dit les fameux ranking factors. Certains de ces signaux sont des “notes”, d’autres des appréciations, d’autres des critères d’évaluation.
Mais s’il n’y a pas de formules magiques, à quoi sert cet article ?
Cet article et ce que dévoilent la fuite de documents va vous permettre de :
- Comprendre comment fonctionne le crawling et l’indexation chez Google ;
- Découvrir certains signaux que semblent capter Google (par exemple, Google flag les sites personnels et les sites de vidéos) ;
- Quelques noms bizarres qui ne vous disent sûrement rien mais qui sont des brique parties intégrantes de l’algorithme (NavBoost, Glue, Chards, etc.) ;
- Démystifier certains secrets notamment autour de l’EEAT ;
- Et confirmer (ou influencer) votre compréhension du SEO et votre stratégie présente et future.
Google Algo Leak : tout ce qu’il faut savoir
La grande difficulté de cette partie c’est de savoir par où commencer… Pour l’instant, cet article ressemble à un fourre-tout, entre mes premières synthèses et ce que je trouve au fur et à mesure que j’explore.
Néanmoins, tout ce que vous trouverez dans cette section “tout ce qu’il faut savoir” est une sorte de résumé au propre et par “catégorie” de mes trouvailles ainsi que des trouvailles des autres.
Un rapide glossaire tout d’abord :
- “NSR” signifierait Neural Search. Ce qui est sûrement la brique qui englobe feu Rankbrain et consiste donc à ce que l’algo utilise du machine learning pour “progresser” ;
- “NS” signifie Nearest Seeds. En fait, la homepage, ou la page “parent” la plus proche ;
L’importance de la thématisation ou topicality
Certains s’en doutaient, d’autres continuaient de persévérer dans le “généraliste”. Mais oui, Google cherche à calculer la thématisation des contenus, au niveau page, domaine, et site. Et aussi la manière dont une page s’inscrit bien dans la thématique d’un site.
On distinguerait donc 5 attributs calculés avec de la vectorisation (les anciens se souviendront du TF-IDF) :
- pageEmbeddings : calculerait le score d’une page dans une thématique précise ;
- siteEmbedding : calculerait un score similaire mais ramené à l’ensemble d’un domaine (sans préciser si on parle de host, domaine, ou seed) ;
- siteFocusScore : une métrique intéressante qui consiste à évaluer à quel point un site se concentre sur une thématique précise. Le document ne mentionne pas si un haut focus est positif ou non ;
- siteRadius : un score d’éloignement qui détermine à quel point une ou plusieurs pages dévient de la thématique de votre site.
Ainsi, nous avons la confirmation que la thématisation d’un site et la proximité entre le sujet de chaque page et la thématique “maîtresse” du site sont des éléments scrutés par Google.
Nota bene : je sais que la notion de score est vraiment très simpliste ici et je prie les copains qui passeront de m’excuser. Je souhaite simplement simplifier au maximum pour que les personnes qui ont mieux à faire de leur vie que du SEO comprennent.

Quelles implications pour votre SEO ?
Difficile à dire, mais si on considère la façon dont un document HTML est décomposé par Google, j’aurais envie de vous pousser à bien améliorer la pertinence sémantique des différents éléments clés d’une page à savoir :
- La balise title ;
- Les headings ;
- Et les ancres de lien internes.
C’est à dire faire en sorte que les 3 éléments ci-dessus soient toujours cohérents les uns avec les autres pour une même page. Bien évidemment, le contenu type paragraphe doit aussi être adapté.
Les balise title comptent toujours
Google calcule un score de pertinence entre votre balise title et la requête. Ce score répond au doux nom de titlematchScore.
Nous aurions pu croire que l’importance de la balise title avait baissé ces dernières années, notamment depuis que Google en réécrit certaines, mais il semblerait que la pertinence de ces dernières vis-à-vis d’une requête soit toujours d’actualité.
A noter qu’il y a même un module dédié aux balises titre de mauvaise qualité ou manquant.


Quelles implications pour votre SEO ?
- Reprenez les données dans votre Google Search Console et comparez votre CTR organique aux “standards” ;
- Comparez les termes sur lesquelles vos pages se positionnent ;
- Questionnez la pertinence entre les termes employés dans les requêtes, l’intention supposé, et votre balise title ;
- Réécrivez-les si cela vous semble pertinent et surveillez le CTR organique sur cette même page.
L’occasion de relire mon guide : Qu'est-ce qu'une balise title et comment l'optimiser avec 8 conseils actionnables.
Les mensonges de Google que le leak dévoile
Pour des “anciens” comme moi, la lecture de cette section m’a fait plaisir car elle m’a permis de me conforter dans ma compréhension de Google. Si vous avez des bases en information retrieval sur des bases de données complexes, vous verrez que les mensonges dénoncés ci-dessous paraissaient évidents. Malheureusement, beaucoup de SEO n’ont pas cette compréhension technique des moteurs de recherche et sont donc victimes des porte-paroles de Google et des influenceurs LinkedIn.
Devons-nous pour autant continuer d'écouter les porte-paroles de Google ? Oui. Les écouter ne veut pas forcément dire les croire ou rejeter ce qu’ils apportent. Mais au même titre qu’il faut trianguler les informations afin d’en vérifier la véracité et la pertinence, les porte-paroles de Google ne sont qu’une source. Il faut donc compter sur la communauté SEO autant que sur les porte-paroles de Google pour affiner votre compréhension du référencement naturel.
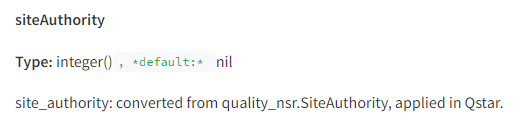
Google a bien une note globale type “Domain Authority”
Google l’a réfuté pendant des années, mais il y a bien dans la documentation un module dédié à une note siteAuthority. Cette note semble être utilisée dans le calcul plus complexe intitulé le Qstar.
Google utilise bien les données des clics et pas que…
Ces dernières années, Google répétait à qui voulait l’entendre que le comportement de l’utilisateur sur les SERPs puis sur vos pages web n’avait aucun impact sur l’appréciation de l’algorithme de ranking.
Ce qui ne faisait aucun sens.
Mon intérêt dans le machine learning a démarré en 2016. Pour tout algo de machine learning, vous devez à un moment instillé un système d’évaluation de sa performance. Quel est le meilleur moyen de dire à un algorithme “tu as bien classé les résultats” ou “tu as mal classé les résultats” ? Le comportement utilisateur. Et plus particulièrement :
- Le taux de clic depuis les SERPs ;
- Le temps passé sur la page ;
- Interactions avec votre page web.
Bref, tout ce qu’un utilisateur qui apprécierait une page web ferait.
Alors j’entends déjà les biberonnés de Google me dire que les Core Web Vitals sont primordiaux etc. Ils le sont, pour le comportement utilisateur notamment. Mais j’ai vu dans un passé pas si éloigné des sites “lents” se positionner devant des sites “rapides” et je pense qu’une cause de cela était la qualité éditoriale de ces sites et la manière dont ils travaillent l’expérience utilisateur (ces sites ont un historique et un profil de liens quasi identiques ainsi que la même stack).
Non seulement le leak nous confirme que Google utilise bien le comportement utilisateur mais que celui-ci est analysé à travers deux systèmes de classement que l’on appelle Glue et Navboost.
Glue est un module qui semble dédié au comportement des internautes sur les résultats de recherche autres que ceux présents dans les SERPs.
Navboost existe depuis environ 2005 selon les auditions menées l’an dernier par le ministère américain de la justice. Son objectif est d’utiliser les signaux captés du comportement de l’internaute pour améliorer (ou non) le positionnement d’un site. Au sein de Navboost, on retrouve un module qui se nomme Craps et qui est particulièrement dédié aux clics et impressions sur les SERPs. On retrouve au sein de Craps la catégorisation suivante :
- Bad clicks ;
- Good clicks ;
- Last longest clicks ;
- Unsquashed clicks ;
- Unsquashed impressions ;
- Unsquashed last longest clicks ;
Le squashing est une fonction qui évite qu’un facteur de positionnement prenne trop de place dans le calcul du positionnement final. En d’autres termes, si vous avez 3 variables dans votre équation, même si 1 variable “explose” à des valeurs incroyables, celle-ci sera pondérée pour ne pas “faire de l’ombre” aux 2 autres variables. Cela permet à l’algorithme d’éviter de se faire influencer par des manipulations sur une variable.

Dans un autre document du leak, Mike a indiqué avoir retrouvé ce type de métrique avec notamment le concept de last good click, de votes, et de durée.
Concernant les “votes”, il semblerait que Google considère les clics des utilisateurs comme des votes (bons et mauvais) segmentés par pays et par type d’appareils (ordinateur, tablette, smartphone).
La notion de “durée” est représentée par les métriques “last longest clicks” qui mesure le temps passé sur une page web après un clic depuis les SERPs.
Enfin, Navboost semble avoir une importance prépondérante dans le positionnement d’une page car il est mentionné de nombreuses fois dans les documents disponibles dans le leak. A noter aussi que celui-ci est calculé séparément au niveau du sous-domaine, domaine, et URL.
Donc comme je le disais plus haut, les comportements dans les SERPs et sur votre page web ont un impact sur le positionnement de votre page. Une raison de plus pour bien travailler son expérience utilisateur ainsi que les balises title de vos pages.
La sandbox des nouveaux sites
Google a toujours maintenu qu’il n’y avait pas de sandbox. En d’autres termes, que l’âge d’un site ne pouvait avoir d’impact sur son positionnement.
Néanmoins, il semblerait que la valeur hostage soit enregistrée et utilisée pour déterminer l’éligibilité de l’host (sous-domaine) à être positionné.
Google utilise bien les données de Chrome pour évaluer les résultats
Imaginez développer le premier navigateur mobile et desktop au monde, duquel vous pouvez obtenir des millions de points de données chaque jour, mais ne pas l’utiliser pour améliorer votre moteur de recherche ?
Aberrant non ?
Et pourtant, c’est bien ce que Google a martelé ces dernières années.
Il était évident que Google pouvait (et devait) utiliser les données des internautes dans Chrome pour mieux analyser la pertinence d’un site internet. C’est logique, c’est du bon sens, et ça donne un avantage compétitif énorme.

Qu’est-ce que le leak Google nous apprend en SEO ?
Panda n’était qu’une simple équation…
M = IL/RQ
Voilà. C’est tout. Merci d’être venu.
Si vous avez été impacté par Panda notamment pendant la première moitié des années 10 (2010 pas 1910), sachez que l’algorithme derrière Panda semblait être beaucoup plus simple que nous le pensions. En fait, la formule consistait à prendre tout un ensemble de signaux extraits du comportement utilisateur et d’autres signaux à partir de liens externes, et de calculer une note (un modifier (M)) qui allait moduler votre note finale et donc votre positionnement.
Il faut comprendre que votre positionnement dans les SERPs est le résultat d’une note. Et que cette note est la somme de centaines d’autres notes issues d’autres “briques” (comme Navboost). Et qu’à la fin, votre note peut encore être modifiée via un modifier telle que celui de Panda.
La page auteur compte

Non, là j’abuse. Peut-être pas la page, mais au moins l’authorship.
J’en parlais notamment dans mon guide dédié à l’E-E-A-T de Google, mais maintenant que Google cherche à évaluer l’expérience réelle partagée dans un contenu, il devient crédible d’accorder de l’importance à l’auteur (d’où la recommandation de créer une page auteur par exemple) afin d’évaluer de la légitimité d’un contenu sur une thématique donnée.
Il semblerait que cela soit confirmé dans la documentation puisque Google enregistre l’auteur (ou les auteurs) d’un document (comprendre, d’une page web).
Une raison de plus pour construire une page auteur (ou “Qui sommes-nous ?”) et refaire votre balise author en vous appuyant sur schema.org.
Il semblerait notamment qu’ils cherchent à faire le lien entre les entités présentes sur une page et l’auteur de la page. Ce qui a du sens puisqu’un auteur qui serait identifié comme “entité” signifie qu’il a une présence forte sur l’internet (on me dit dans l’oreillette que certains veulent une page Wikipédia ?).
Éléments pénalisants
Quelques éléments retrouvés par Mike dans la documentation mais sur lesquels il n’a pas encore trouvé plus d’informations. Je conserve le terme de demotion en Anglais que l’on pourrait traduire par “déclassement”, “pénalité”, “rétrograde”.
- Anchor Mismatch Demotion : lorsque le lien ne correspond pas au site cible auquel il renvoie, le lien est “déclassé” / “rétrogradé” dans les calculs ;
- SERP Demotion : il y a bien une notion de “rétrograde” du positionnement d’un site web si celui-ci semble ne pas satisfaire les internautes. Encore une fois, cela montre bien l’importance des signaux utilisateurs ;
- Nav Demotion : Il s'agit vraisemblablement d'une pénalisation appliquée aux pages présentant de mauvaises pratiques de navigation ou des problèmes d'expérience utilisateur ;
- EMD Demotion : il fût un temps que les plus jeunes ne connaîtront jamais où avoir un exact match domain (EMD) permettait de se positionner plus facilement sur la requête concernée. Cette “puissance” a été considérablement réduite (voire pénalisée) au cours ds 10 dernières années.
- Product Review Demotion : mentionné dans la documentation mais sans plus de détails. Mike pense que cela a un lien avec la mise à jour Product Review d’Avril 2023.
- Location Demotion : Il semblerait que Google souhaite à tout prix rattacher une page web à une localisation et pourrait pénaliser les pages globales sans aucune référence géographique.
- Porn Demotion qui se passera d’explication ;
- Les liens, sujet dont nous allons traiter ci-dessous.
L’impact des liens selon le Google algo leak
Puissance des liens
Pour Google, les pages sont catégorisées en plusieurs strates que l’on appelle des tiers :
- Top Tier : page de haute qualité dont le contenu est souvent mis à jour et est stocké sur un flash drive.
- Medium Tier : page de qualité moyenne, stockée sur des SSD.
- Low Tier : contenu mis à jour de manière irrégulière (et rare), stocké sur un disque dur HD.
Cette catégorisation en 3 tiers est simplement pour faciliter la compréhension.
Tout ça pour dire que selon la documentation, un lien venant d’une page positionnée dans le top tier aura plus de valeur qu’un lien provenant d’un low tier. En d’autres termes, il vaut mieux avoir un lien d’un important média national que du blogueur du coin.
Ce n’est pas une grande nouvelle vous me direz, mais ça valide en tout cas ce point de connaissance.
Vélocité du link spamming
Et ceci pourrait expliquer pourquoi Google déconseille de plus en plus d’utiliser l’outil de désaveu des liens de la Google Search Console.
Il semblerait selon le leak que Google calcule le nombre de liens externes obtenus sur une courte période par rapport à la tendance des dernières années, et ce afin d’identifier une attaque potentielle de negative SEO en utilisant des liens spammy.
En d’autres termes, si vous gagniez environ 10 liens par mois et que Google en compte 1500 nouveaux de faibles qualité sur les derniers jours, il est très probable que ceux-ci soient considérés comme spammy et n’impactent donc pas négativement votre domaine.
Homepage PageRank
Chaque page web a une métrique assignée appelée Homepage PageRank. Cela signifie que pour n’importe quelle page, Google considère le PageRank (la note ultime) de la page seed c’est à dire la page parent.
Par exemple, la page seed d’une fiche produit c’est la page catégorie.
Ce qu’est plutôt une bonne chose notamment pour les nouvelles pages qui n’ont pas encore de PageRank, elles bénéficient alors du PageRank de leur page parent dans l’intervalle.
Homepage Trust
La valeur d’un lien dépend du niveau de confiance que Google a dans la page d’origine. Ce n’est pas une nouveauté, et ça rejoint ce que j’écrivais plus haut. Donc, favorisez la pertinence et la qualité plutôt que la quantité.

La taille des fonts et des ancres de lien compte
Surprenant. Mais il semblerait en effet que Google calcule :
- La taille moyenne des fonts d’un document HTML (comprendre page web) ;
- La taille moyenne des fonts d’une ancre de lien.
Google est capé dans le nombre de caractères qu’il considère sur votre page web
Google attribue un nombre de tokens par page. Un token c’est comme un caractère. Google semble avoir une limite maximum dans le nombre de tokens ce qui signifie qu’un contenu trop long pourrait ne pas être considéré dans sa totalité.
Néanmoins, nous n’avons aucune information de ce qu’est un contenu trop long.

L’originalité comme métrique d’évaluation des contenus courts
Qu’est-ce que l’originalité selon une machine ? Aucune idée.
Mais en tout cas, pour des contenus courts, il semblerait que cette métrique soit considérée dans le positionnement

Les dates comme marqueurs de pertinence
C’est une demi-surprise. C’en est une car je ne pensais pas que Google prêtait autant d’attention au point d’avoir 3 attributs dates différenciés. Ce n’en est pas une car c’est logique.
Google semble stocker trois attributs de datés différents :
- bylineDate : qui n’est autre que votre date de publication.
- syntaticDate : qui est la date extraite du slug ou du titre de votre contenu (il est temps de changer tous vos guides 2023 en guides 2024) ;
- semantic Date : qui correspond aux dates mentionnées dans un document.
Pourquoi est-ce logique ? Les dates permettent de rassurer Google sur la fraîcheur d’un contenu et aussi sa pertinence. Entre un contenu publié en 2015 et qui cite des articles des années 2000 et un contenu publié en 2024 citant des articles des années 2000 et 2010, l’article qui semble plus “frais” et donc pertinent serait le plus récent.
Qu’est-ce qu’on en retient ?
- Mettez à jour vos contenus et vos sources ;
- Assurez-vous d’être cohérents sur les dates utilisées dans vos données structurées, vos titres, vos sitemaps, etc.
La date d’enregistrement d’un domaine compte
Ou en tout cas c’est une donnée stockée. Pourquoi est-ce plausible ?
Tout d’abord, c’est une donnée publique sur internet. N’importe qui peut utiliser un Who Is pour retrouver la date de premier enregistrement d’un domaine ainsi que la date de changement de propriété d’un domaine.
Ensuite, puisque cela aurait du sens compte tenu de la sandbox que nous évoquions plus haut pour les nouveaux sites, mais aussi par rapport aux récents efforts déployés par Google pour lutter contre l’usage des domaines expirés.
Les sites video-first sont traités différemment
Je pense que peu d’entre nous sont concernés ici mais si plus de la moitié de vos pages ont une vidéo, votre site est considéré comme video-focused. Quel impact réellement ? Aucune idée.

Les petits sites type blog sont identifiés
Sans bien que l’on sache pourquoi et quel impact cela a, Google semble flag les petits sites personnels type blog.
YMYL a un scoring modulé
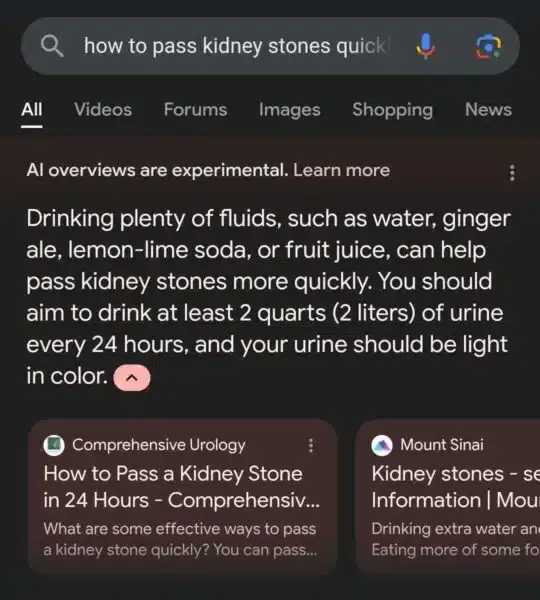
Si vous êtes dans la niche YMYL (Your Money Your Life), en d’autres termes, en lien avec des sujets de santé ou de finance, Google utilise un score en plus pour le considérer.
Ce n’est pas une surprise puisque le YMYL a toujours été considéré comme un élément à part entière à traiter différemment comme on le voit dans les Search Quality Raters Guidelines.
Ce serait bien qu’ils s’en souviennent d’ailleurs avec leur intelligence artificielle qui recommande de boire 2 litres d’urine toutes les 24 heures pour vous débarrasser de vos calculs rénaux.
Google considère bien la thématique d’un site
Google semble vectoriser chaque page d’un site par rapport à l’ensemble du domaine afin de calculer la proximité sémantique des pages entre elles et donc à quel point une page web d’un domaine peut être hors sujet.
Comment utilisent-ils cette information ? Nous ne le savons pas mais nous savons depuis toujours que la vectorisation des contenus est utilisée pour classifier des contenus les uns par rapport aux autres, et que ceci est aussi utilisé au sein d’un même domaine.
Ainsi, si un site spécialisé dans les fleurs publie un super guide sur le javascript seo, il y a peu de chances que ce contenu-là se positionne même si le site est puissant.
En résumé
Le 5 mai 2024, des documents internes de Google ont été divulgués, révélant des informations précieuses sur le fonctionnement de l'algorithme de recherche. Rand Fishkin a reçu ces documents d'une source anonyme et les a partagés avec Mike King de iPullRank, qui a commencé à analyser et publier les informations.
Ci-dessous sont les principaux éléments que l’on peut trouver dans le leak (tout le crédit revient à Mike).
- Le leak intègre 14 014 features répartis dans 2596 modules qui agissent de manière autonomes afin d’évaluer différentes dimensions pour au final consolider un score ;
- Domain Authority : Google utilise bien une métrique de domain authority même si nous ne savons pas précisément en quoi elle consiste (je subodore une question de thématisation de domaine et puissance) ;
- Données de comportement des utilisateurs : Google utilise les données de clics depuis les SERPs et le comportement d’utilisateurs pour évaluer la pertinence de son ranking et d’une page web ;
- Meta Title : la pertinence entre le contenu d’une balise titre et une requête par un utilisateur fait l’objet d’un scoring.
- Thématique du site : la thématique d’un site et de chaque page du site est calculée par Google lui permettant d’identifier un score de pertinence sémantique.
- Impact des liens : Google valorise mieux les liens provenant de page de haute qualité ;
- Attaques de liens spammy : Google semble en mesure d’identifier les attaques de negative SEO et de les ignorer pour ne pas affecter le positionnement d’un site ;
- Pertinence thématique des liens : un lien provenant d’une thématique éloignée de la page ciblée a moins de puissance.
- Importance de l’Authorship : dans la lignée des directives de l’EEAT, Google enregistre l'auteur d'un document pour sûrement évaluer la légitimité du contenu ;
- Sandbox : Les nouveaux sites semblent bien être positionnés dans une sandbox. Le cloisonnement semble aussi exister pour des sites spammy (une espèce de shadow ban) ;
- Google a une limite de tokens qu’il peut considérer par document (donc la longueur), mais cette limite n’est pas précisée.
- Utilisation des données Chrome : Google utilise les données collectées par le navigateur Chrome pour évaluer la pertinence des sites, malgré des déclarations contraires ;
- La taille de la police d’écriture semble être considérée, y compris la taille de vos ancres de lien ;
- L’importance des dates : Google semble traiter les dates comme des entités que ce soit la date de publication, la date mentionnée dans un titre, dans le contenu, ou même dans un slug ;
- La date d’enregistrement d’un domaine est considérée ;
- Les sites dont plus de la moitié des pages comportent une vidéo sont considérés comme des sites video focused ;
- Google flag les petits sites type blog.
Tout comme avec le Yandex link l'an dernier, les documents qui ont fuité ici ne représentent qu'une vue partielle de l'algorithme de Google. Néanmoins, les informations qu'on y retrouve restent sujettes à précaution. Déjà parce qu'elles ne donnent pas la formule magique, donc on ignore toujours exactement comment est calculé une position, mais aussi parce qu'on n'a aucune idée de l'importance des différents éléments qui ont été analysés. Par exemple : oui Google a une métrique de domain authority mais comment celle-ci est calculée et utilisée ?
Ce leak fait donc du bruit, ce qui est compréhensible, mais il ne livre pas de formule magique. Toutefois, je reconnais qu'il conforte certaines positions que j'avais dans ma compréhension de Google.
Qu'est-ce que ce leak change pour moi ?
Ce leak me conforte surtout dans ma compréhension du fonctionnement de Google. Si je devais me faire une liste d'actions, je dirais :
- Vérifier le CTR depuis les SERPs et retravailler mes balises titre si je sais que je suis "léger" ;
- Affiner mon profil de liens pour capturer des liens de qualité et qui correspondent à ma thématique ;
- Retravailler l'expérience utilisateur et pas seulement les Core Web Vitals ;
- Renforcer mon E-E-A-T et cela ne passe pas que par l'authorship bien évidemment.
Fondamentalement, ce leak confirme plus de choses dans mes stratégies SEO que ne m'apporte de surprise (à part la taille des polices pour être tout à fait franc). Donc cela n'aura pas un impact particulier sur mon "opérationnel", mais je serais néanmoins plus pointu sûrement sur certains sujets. Enfin, je fais partie des "anciens" du SEO, ceux qui ont été constamment désavoués puis adorés par Google, ceux qui ont adapté leurs stratégies selon ce qu'on observait. Il y a des concepts fondateurs et fondamentaux à comprendre dans le référencement naturel qui aident à garder une ligne directrice et à faire la part des choses entre le bruit des annonces et des influenceurs, et ce que doit être un moteur de réponses (et de recherche).
Newsletter
Les actus SEO & GEO chaque mois
Aucun spam. Les derniers insights directement dans votre boîte mail.
Questions fréquentes
Qu'est-ce que le leak de documents de la division Google Search ?
Le 05 Mai 2024, un inconnu a partagé à Rand Fishkin des milliers de documents issus de la base de données de la division Google Search. Rand, après avoir vérifié la crédibilité de ces leaks, les a partagés à Mike King de iPullRank qui a partagé les premiers points-clés le 27 Mai 2024.
Que faut-il retenir du leak de Google ?
De nombreuses choses : tout d'abord, Google via ses porte-paroles entretient des mythes voire partage des information erronées auprès de la communauté des SEO. Sûrement dans l'objectif d'éviter aux professionnels du référencement naturel de trop manipuler l'algorithme. On apprend (ou confirme des intuitions) que le comportement des internautes a un impact sur la qualité perçue d'un site, que les liens sont importants et doivent être thématisés, ou encore que l'âge d'un domaine est un facture considéré par Google.
Le lead fournit-il la formule magique ?
Tout comme pour Yandex, ce leak est partiel. Beaucoup de documents complémentaires sont manquants (ce qui est compréhensible) ou accessibles seulement depuis l'intérieur de Google. Donc non, vous ne pouvez pas espérer obtenir la formule magique pour vous positionner #1 sur Google à partir de ces leaks. Mais vous pouvez néanmoins en profiter pour réviser vos connaissances / croyances voire apprendre de nouvelles choses sur Google et son fonctionnement.







Partagez votre avis, vos questions, vos recommandations ci-dessous