Javascript SEO : le guide complet pour un bon référencement naturel

Ce qu'il faut retenir
EN RÉSUMÉ
Le JavaScript SEO consiste à profiter de l’interactivité du JavaScript sans sacrifier l’exploration, l’indexation et le positionnement des pages. Le guide explique pourquoi les sites en Client-Side Rendering peuvent poser problème : Google doit récupérer, analyser et exécuter le JavaScript avant de voir le contenu et les liens internes. Cette complexité consomme du crawl budget et peut entraîner des contenus invisibles, des pages orphelines ou des redirections mal comprises. Les bonnes pratiques consistent à privilégier le SSR ou le pre-rendering, rendre les liens en HTML, éviter les URLs avec #, surveiller le robots.txt, le lazy loading et la performance.
Le JavaScript SEO vise à rendre les sites en JS accessibles, crawlables, indexables et performants pour les moteurs.
Le principal risque vient du Client-Side Rendering, qui oblige Google à exécuter le JavaScript pour comprendre la page.
Les liens internes doivent être rendus en HTML statique avec des balises <a href> pour être correctement suivis.
Le SSR, le pre-rendering, des URLs propres, un robots.txt ouvert et des performances optimisées limitent les risques SEO.
1h de coaching avec un expert
Réserver mon coaching
DÉBUT DE L'ARTICLE
Javascript a permis de rendre le web bien plus dynamique et interactif. L'expérience utilisateur (UX) devenant de plus en plus importante pour les propriétaires d'applications (web et mobile), il est tout à fait normal que ce langage se répande. Nous le retrouvions déjà depuis bien longtemps sur certaines animations basiques telles que l'ouverture d'un menu par exemple, mais il prend ces dernières années de plus en plus de place.
Néanmoins, bien que le Javascript ait de nombreux avantages sur l'expérience utilisateur, l'usage des ressources, ou encore la prise en main côté dev, ce langage peut rapidement devenir un cauchemar pour le référencement naturel. L'objectif de ce guide est de vous permettre de comprendre comment "SEO et Javascript" fonctionnent ensemble, et de vous apprendre comment vérifier que le Javascript n'endommage pas votre référencement.
Qu'est-ce que le Javascript SEO ?
Le Javascript SEO est une discipline du SEO Technique qui cherche à optimiser les sites développés en Javascript afin de :
- garantir que votre site est accessible aux robots des moteurs de recherche ;
- vous assurer que vous couvrez les bases des bonnes pratiques du SEO (metadata, robots.txt, etc.) ;
- préserver l'internal linking ;
- anticiper, repérer, et corriger les problèmes d'indexation et de positionnement notamment sur Google des sites internets et autres SPAs (Single Page Applications) construites avec des frameworks tels que React, Angular, Vue, Next, et d'autres ;
Bref, tout pour profiter du meilleur du Javascript (l'interactivité et la vitesse) sans sacrifier le SEO.
Avec en bonus :
- si vous êtes dev : ne pas vous embrouiller avec votre équipe marketing qui se plaint de votre SPA (Single Page App) ;
- si vous êtes marketeur : ne pas vous embrouiller avec votre équipe technique.
Pourquoi les sujets de Javascript et SEO sont importants de nos jours ?
En 2020, le célèbre forum d'entraide pour développeurs Stack Overflow réalisa une étude sur la popularité des langages de programmation auprès de sa communauté. Sans surprise, ce fut Javascript qui arriva en tête.

Ainsi, de plus en plus de sites internets sont construits en utilisant du Javascript. Mais malgré la popularité de ce langage, la performance SEO de la plupart de ces sites est décevante.
Alors pourquoi s'évertuer à utiliser ce langage ?
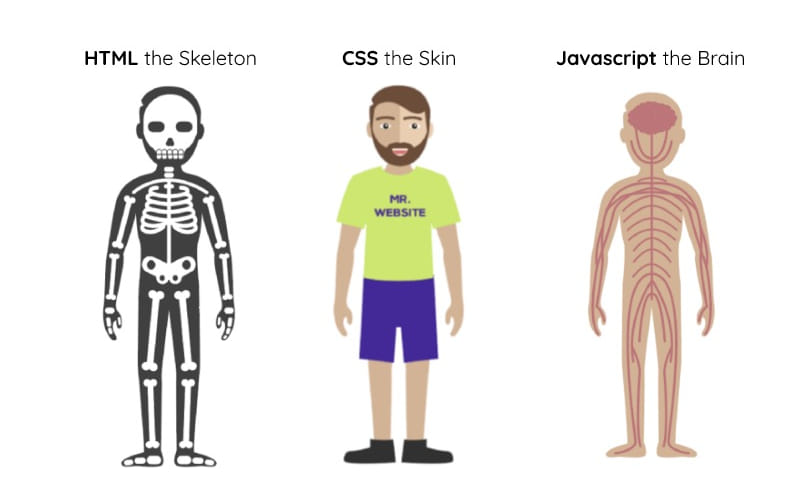
Bonne question ! Après tout, nous parvenions à créer des sites en utilisant uniquement du HTML et du CSS. Mais ces deux derniers restent quand même très limités.
- HTML permet de définir le squelette de votre page
- CSS permet de le "styliser"
- et Javascript de le rendre interactif
Le Javascript est d'ailleurs quelque chose que l'on retrouve déjà depuis très longtemps pour gérer notamment :
- la pagination ;
- les contenus dynamiques tels que les filtres d'un e-commerce ;
- les avis ;
- l'internal linking de manière dynamique ;
- la gestion des commentaires ;
Donc oui, le Javascript n'est pas forcément le plus facile pour le SEO, mais est déjà bien présent.
Comment savoir si mon site utilise du Javascript ?
Tous les sites intègrent aujourd'hui du Javascript. Mais ici nous parlons des sites qui sont construits entièrement (ou presque) sur du Javascript. Afin de savoir si votre site est construit en Javascript, vous pouvez utiliser ces deux extensions Google Chrome BuiltWith ou Wappalyzer. Une fois installés, vous pouvez accéder à la liste des technologies utilisées par un site internet. Les principaux frameworks que vous rencontrerez seront :
- Angular
- React
- Vue
Une autre option pour vous renseigner consiste simplement à demander à votre équipe de développeurs.
Pour comprendre comment gérer le Javascript et le SEO, il est important de comprendre quelques bases sur le fonctionnement d'un site web en Javascript.
Comment fonctionne un site web en Javascript ?
Tout d'abord, nous allons définir ce qu'est un DOM. Le DOM (Document Object Model appelé en français le modèle d'objets de document) est le fichier transmis par le serveur à votre navigateur pour que celui-ci le traduise en une interface que vous comprenez. Lorsqu'un site repose sur du Javascript, le contenu dans le DOM est mis à jour via le Javascript.
Mais cette façon de faire peut poser un problème dit de rendering ("rendu" en français).
Server Side Rendering versus Client Side Rendering
Le rendering est la façon dont un document est rendu pour interprétation au navigateur ainsi qu'aux robots d'un moteur de recherche. Ce dernier peut donc s'effectuer de deux façons :
- SSR (server-side rendering) : approche traditionnelle
- CSR (client-side rendering) : approche moderne notamment grâce au JavaScript et sa façon de mettre à jour le DOM
Mais qu'est-ce que le Server Side Rendering ?
Dans la méthode traditionnelle, votre navigateur (chrome, safari, etc.) reçoit un document HTML qui décrit parfaitement la page. Ainsi, l'ensemble du contenu de la page est déjà présent. Pour votre navigateur, il n'a qu'à afficher ce qu'on lui demande. De leur côté, les robots des moteurs de recherche n'ont en général aucun problème avec ce type de rendering.
C'est quoi le Client Side Rendering ?
À l'inverse du SSR, le CSR envoie à votre navigateur (le "client") un premier document HTML qui est souvent très pauvre. Puis dans un second temps, par la magie du JavaScript, le DOM est mis à jour avec le contenu complet. Pour votre navigateur, la gymnastique se fait en deux étapes quasi simultanées et il le fait très bien. Néanmoins, du côté des robots dont Googlebot, c'est souvent là que les problèmes arrivent...
Vous pouvez répéter la question ?
Pour être certain de me faire comprendre, prenons l'analogie d'une recette de gâteau au chocolat.
- Server side rendering : votre serveur envoie au navigateur et aux robots un gâteau tout préparé prêt à manger.
- Client side rendering : votre serveur envoie au navigateur et aux robots la recette du gâteau puis les ingrédients. La gymnastique est aisée pour votre navigateur, moins pour les robots.
Pourquoi Google a des difficultés avec les sites en Javascript ?
Car il est fainéant ! Bon, c'est un poil plus complexe que ça mais on va y venir.
Mais enfin Quentin, Google n'a-t-il pas dit qu'il était capable d'indexer du Javascript ?
En effet, il l'a dit. Il l'a dit... Eh oui... Il l'a même annoncé en 2017 si mes souvenirs sont bons. Mais comment dire.... Il y a ce que Google annonce, et ce que techniquement ils parviennent à faire. Encore aujourd'hui, certains grands sites e-commerce tels que Sephora ont une partie non négligeable de leur contenu qui n'est pas indexée. Alors oui, il l'a dit. Mais aujourd'hui encore, nous observons certains sites - pourtant bien connus - construits en Javascript et qui font face à certains problèmes d'indexation. Alors que pour d'autres plateformes, tout se passe bien. Il y a deux éléments de réponse pour comprendre :
1. Comment Google crawl le Javascript ?
Permettez-moi de vous présenter d'abord comment Google crawl un site "HTML traditionnel" :
- Googlebot demande au serveur le document HTML
- Une fois le document téléchargé, il en extrait des liens internes et externes
- Googlebot télécharge ensuite le fichier CSS
- Il envoie l'ensemble de ces documents à Caffeine (c'est le nom de l'indexeur de Google)
- Caffeine décide d'indexer la page
Passons maintenant à l'exploration de sites en Javascript :
- Googlebot demande au serveur le document HTML
- Il télécharge le document mais ne parvient pas à trouver de liens car ces derniers étaient injectés a posteriori via du Javascript
- Googlebot télécharge le fichier CSS puis les fichiers JS
- Googlebot doit alors appeler le Google WRS (Web Rendering Service) pour analyser (vous avez peut-être déjà entendu le terme de parsing en anglais), compiler, et exécuter le Javascript
- Le WRS récupère alors les informations "manquantes" en exécutant le JS et effectue le rendering.
- Caffeine peut alors indexer le contenu
- Googlebot découvre finalement les liens et peut les ajouter dans la file d'attente de ressources à explorer du Googlebot.
Très rapidement, vous pouvez constater qu'il y a plus d'étapes lorsqu'on touche à des sites en JS. L'intégralité du process est plus long et plus complexe, ce qui requiert plus de ressources. Le Googlebot n'a pas une infinité de ressources pour son crawl, il vous dédie un quota (crawl budget) et s'il ne parvient pas à découvrir l'ensemble du contenu avec ce budget, tant pis... Il reviendra sûrement si le contenu s'il a jugé le contenu découvert pertinent. Après quant à la date de son retour...
En résumé, que faut-il retenir ?
- L'analyse, la compilation, et l'exécution du JS consomment beaucoup de ressources et prennent du temps ce qui déplaît à Google (et peut déplaire à vos utilisateurs aussi) car cela mobilise ses robots chez vous.
- À cause de cette sur-consommation, la fréquence d'exploration ainsi que le nombre de pages que le Googlebot souhaite et peut explorer (crawl budget) peut être impacté.
- Google ne peut indexer le contenu JS que si le site a été entièrement rendu (les contenus ont été crawl, et le JS exécuté). Du coup, s'il consomme son budget trop tôt, trop vite, je vous laisse imaginer.
- Google découvre les pages et les sites du web grâce aux liens. Si ces derniers (surtout les internes) sont exécutés que via du Javascript et donc "découvrables" qu'en fin de process, cela peut impacter votre maillage interne.
2. Googlebot ne se comporte pas comme un navigateur normal
Quand vous souhaitez accéder à un site internet en Javascript via votre navigateur, ce dernier télécharge l'ensemble des ressources des pages que vous visitez (et par ressources, j'entends les médias type images, vidéos, les scripts JS, et les fichiers CSS). Et puis surtout, votre navigateur "a le temps". Vous lui donnez un ordre, ouvrir une page d'un site en JS par exemple, il s'exécute. Mais si nous repensons à nos robots d'exploration, eux n'ont pas le temps. Ils sont en ressources limitées pour découvrir chaque jour une quantité incroyable de pages sur le web. Ainsi, Google doit faire le tri dans ce qu'il accepte de récupérer et "analyser". D'ailleurs, assez rapidement, Google a officiellement reconnu que si des éléments de JS ne semblaient pas impacter réellement le rendu de la page, il n'allait pas les récupérer.
Maintenant, imaginons que le script JS qui injecte les liens dans vos pages soit considéré peu important, et de fait le Googlebot ne le récupère pas ? C'est exact, jamais Google ne verra vos liens internes et adieu le maillage interne. Ou imaginons que vos FAQs de bas de page mettent trop de temps à s'exécuter ou que le Googlebot a déjà dépensé trop de ressources pour récupérer d'autres éléments ? Dans ce cas vos FAQs ne sont pas indexées, et ne le seront peut-être jamais (adieu position 0 ?). Tout comme le fait que Google peut avoir exécuté votre Javascript une fois et décidé de ne plus le faire car il trouvait que cela n'apportait rien au rendering (adieu les sections "produits similaires" générées dynamiquement).
Maintenant que nous avons vu pourquoi le JS pouvait rendre le travail de Google plus difficile, regardons les bonnes pratiques.
Javascript SEO : quelles bonnes pratiques pour réussir ?
Que j'aurais aimé avoir ce guide à mes premières rencontres avec des sites en JS... (big up à Angular 1, développé pourtant par les équipes de Google, mais qui n'était pas SEO-friendly).
Avant toute chose : mon contenu est-il indexé sur Google ?
On vous épargne les dizaines de points de contrôle d'un véritable audit SEO, mais voici deux façons simple de vérifier si votre contenu est indexé lorsque vous intervenez sur un site déjà live depuis quelques semaines voire mois.
Méthode 1 : avec l'opérateur de recherche "site:"
A effectuer en mode incognito dans un navigateur qui utilise Google.
Méthode 1.1 : Vérifier la présence de la page dans l'index Google :
Pour vérifier que la page qui vous intéresse est présente dans l'index de Google, et donc dans les résultats de recherche, vous utilisez l'opérateur de recherche avec le format suivant "site:URL" (URL étant l'adresse de la page que vous cherchez).
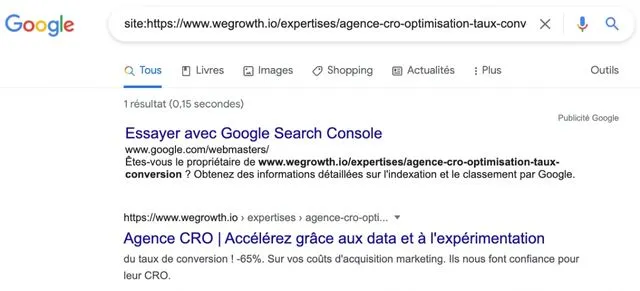
Méthode 1.2 : Vérifier que Google a bien indiqué le contenu de la page en question
Dans ce cas là, il suffit de prendre une partie du contenu textuel, et de vérifier qu'il a bien été pris en compte dans le contenu indexé. Je vous conseille de tester plusieurs morceaux de contenu :
- contenu en haut de page
- contenu dans des modules "dynamiques" (par exemple les modules "d'articles similaires")
- contenu en bas de page (avant le footer bien évidemment)
Dans l'exemple ci-dessous, j'ai extrait une phrase d'une des dernières sections de la page, je l'ai placée entre guillemets suivie de la commande "site:URL". Littéralement, j'indique dans la barre de recherche, chercher la phrase exacte (la portion entre guillemets) sur cette page précise (l'URL après site:).

Bien évidemment, ne vous limitez pas qu'à une page et qu'un morceau de texte.
Méthode 2 : via la Google Search Console
La Google Search Console est un outil trop peu maîtrisé mais qui offre d'excellentes fonctionnalités et peut apporter de précieuses informations à qui sait l'utiliser.
Dans l'onglet "Inspection de l'URL", vous pouvez saisir l'URL exacte de votre page puis cliquer sur "Entrée". Non seulement, la Google Search Console va vous indiquer si la page est indexée, mais si vous cliquez sur "AFFICHER LA PAGE EXPLORÉE" vous pouvez alors accéder à plusieurs autres fonctionnalités.
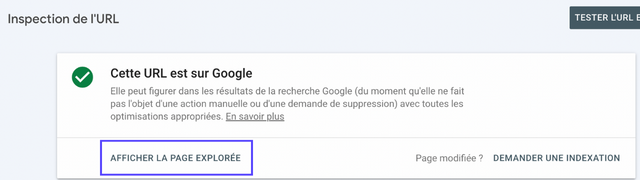
En effet, vous retrouverez sur le côté droit une pop-in avec le document HTML que les robots ont récupéré. Vous pouvez alors utiliser la fonction recherche, et tenter de retrouver dans le code l'élément en question (une phrase, un sous-titre, un alt text, un lien par exemple).
Que faire si mon contenu n'est pas indexé par les moteurs de recherche ?
Il peut y avoir plusieurs raisons qui expliquent cela :
- Un contenu considéré comme peu qualitatif
- Googlebot qui a un timeout en cherchant à crawl votre site (problème de performance technique de votre côté)
- Des problèmes de rendu (que vous devriez voir avec la Google Search Console)
- Le crawler a peut-être décrété que vos fichiers JS n'étaient pas pertinents à exécuter (malheureusement c'était votre core content)
- Google ne parvient pas à trouver votre page (problème de maillage interne, de déclaration de sitemap)
- Blocage des ressources JS via le robots.txt
Mais tout n'est pas perdu. Javascript et SEO nécessitent de la rigueur et de la discipline dans l'exécution. Je vous propose ainsi dans les paragraphes ci-dessous différentes vérifications et pistes pour améliorer le référencement de votre site.
1. Vérifier / optimiser votre rendering
Favoriser le pre-rendering (Server-side rendering / Hybrid Rendering / Dynamic Rendering)
Server-side rendering (SSR) : Comme vous l'avez sûrement compris, il faut faciliter le travail des robots d'exploration et ces derniers vous le rendront. Ainsi, si vous avez bien suivi l'analogie de la recette, vous comprendrez qu'il vaut mieux qu'un maximum d'efforts soit réalisé au préalable côté serveur (dont l'exécution du Javascript), plutôt que du côté "client". Alors, je ne parle pas de tout le Javascript, mais au moins de ce qui est core content (par exemple le texte, les images, et les liens d'un article de blog).
Selon le framework JS que votre équipe tech a choisi, les solutions de SSR peuvent différer. Voici celles que je connais :
Framework JS et solutions de SSR
- React --> Next.js / Gatsby
- Angular --> Angular Universal
- Vue.js --> Nuxt.js
Hybrid Rendering : Comme son nom l'indique, le but est de faire en sorte que le core content soit rendu en SSR, et que le reste (ex : les articles similaires) le soient en Client-Side Rendering. Personnellement, je ne suis pas fan. Comme tout ce qui est hybride, cela nécessite une compréhension des deux systèmes, une attention particulière à chaque ajout de nouvel élément. Je trouve que l'on a vite fait de tout mixer et de s'y perdre.
Dynamic Rendering : Ici, le but est de servir aux utilisateurs une version JavaScript telle qu'initialement codée, et en parallèle une version déjà "rendered" par un service tiers aux robots d'exploration (basé sur le "user-agent"). Pour effectuer ce dynamic rendering, vous pouvez utiliser une des solutions suivantes :
- Renderton (recommandé par les Google Webmasters et open-source)
- Prerender.io
- Puppeteer
Bien que cela puisse rappeler à certains d'entre nous le cloaking, Google valide cette méthode et y a même dédié un guide complet (ce qui est plutôt rare).
La règle d'or, en fait, est de ne jamais toucher le DOM.
De mon côté, j'ai toujours préféré le SSR. Mais cela dépend de vos contraintes (le SSR demande certaines ressources côté serveur) et des préférences de vos équipes.
2. Vérifier la crawlabilité de mon site par les robots d'indexation
Ce point rejoint la partie d'avant. Nous écrivions plus haut que Googlebot ne se comporte pas comme un navigateur normal. Il récupère d'abord le fichier HTML avant d'exécuter le JS. Ainsi, il est pertinent de vérifier ce à quoi ressemble votre site internet sans Javascript, et s'il est navigable (sous réserve d'avoir une solution de pre-rendering). Pour ce faire, vous pouvez utiliser deux extensions Chrome :
Grâce à ces extensions, vous désactivez l'exécution du JS sur votre site. Comme cela, la page que vous voyez s'afficher correspond au document initial que récupère le Googlebot (sans JS).
Si la page est blanche, vous êtes mal. C'est sûrement que vous n'avez pas de pre-rendering (SSR, dynamique, ou hybride). Si votre page s'affiche normalement (à peu de choses près) alors essayez de naviguer en cliquant sur vos liens internes et sur certains éléments d'interaction (par exemple la pagination d'un catalogue e-commerce). Si la navigation se fait normalement, tout va bien. Ne vous inquiétez pas si certains éléments qui dépendent d'animations en JS ne fonctionnent plus telle que l'ouverture d'un accordéon de FAQ. Dans ce cas précis, il est préférable de vérifier dans la Google Search Console si le contenu de la FAQ est bien récupéré.
3. Javascript SEO et internal links
Et là les amis, c'est mon paragraphe préféré. Ca va être court, mais ça va être intense. J'ai vu des projets de groupes côtés en bourse échouer en SEO pour le petit détail que je vais vous exposer ci-dessous : un lien interne qui n'a pas de balise <a href > dans le code et est exécuté via du JS, ne sera pas compris ni suivi par les Googlebot.
De fait, aux yeux des moteurs de recherche, chaque page de votre site est orpheline. Les pages n'étant pas liées entre elles, la puissance SEO n'est pas distribuée, le glissement sémantique entre pages n'est pas perçu. Vous l'aurez compris, votre performance SEO sera proche de 0. C'est quelque chose que vous pouvez déceler assez rapidement en désactivant le JS comme indiqué dans la partie précédente. Donc, on render les liens en "statique" !
Ce que Google indiquait déjà en 2018 dans sa I/O Conférence est toujours valable aujourd'hui :
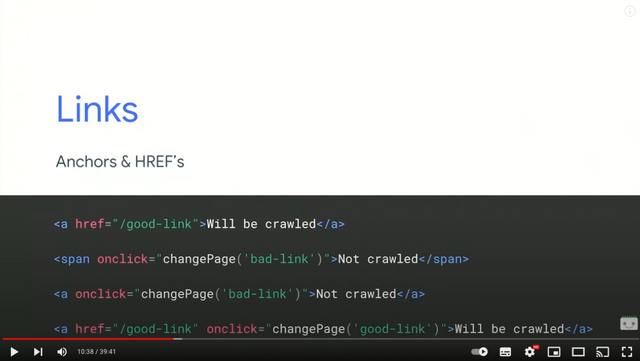
Si vous vous rappelez ce que j'ai dit plus haut, Google ne se comporte pas comme un humain ou un navigateur normal. Donc, tout lien conditionné à une action comme c'est le cas avec <a onclick> ne pourra s'exécuter et être découvert. Par conséquent, faites attention aussi à vos paginations (n'est-ce pas les sites e-commerce ?).
4. Redirections en Javascript
Il peut arriver que pour certaines raisons, votre équipe technique rajoute un subfolder dans votre URL. Parfois, pour faciliter le content grouping dans vos outils d'analyse par exemple.
- Le lien <a href> dans le DOM est https://www.mondomaine.fr mais lorsqu'on clique sur ce lien, la page qui s'ouvre devient https://www.mondomaine.fr/fr/ (assez courant pour des web apps multilingues en mono repo)
- Le lien <a href> dans le DOM est https://www.mondomaine.fr/mon-article mais lorsqu'on clique sur ce lien, la page qui s'ouvre devient https://www.mondomaine.fr/tag-1/mon-article
Si vous voulez savoir si la redirection à laquelle vous faites face est une Javascript Redirection, reprenez une des deux extensions Chrome que j'ai partagé plus tôt (telle que Web Developer), désactivez Javascript, cliquez sur le lien, et regardez le résultat. Si la page est blanche et l'URL inchangée, vous avez une redirection Javascript. Si la page s'ouvre, l'URL change, et le contenu charge, vous avez une direction server-side 301 ou 302.
Rappelez-vous ce que nous avons dit plus tôt. Le Googlebot n'exécute pas immédiatement le JS et a besoin de faire appel au WRS. Mais le WRS n'intervient jamais immédiatement dans l'exécution du JS (et parfois n'intervient pas du tout s'il pense que cette redirection n'a pas d'intérêt). De cette façon, il y a de fortes chances que le contenu de cette page redirigée ne soit pas découvert via le maillage interne (au mieux, tardivement).
De manière générale, les redirections Javascript et le SEO ne font pas bons ménages. Donc, si vous souhaitez implémenter des redirections, implémentez-les 301 (ou 302) en server-side !
5. Présence de hash (#) dans les URLs
La présence de hash (#) n'est pas une chose rare dans les sites en Javascript. C'est souvent une histoire de configuration de router et d'URLs dynamiques. Néanmoins, Google considère que tout ce qui vient après un "#" est inutile et pas pertinent.

- Mauvaise URL : https://www.mondomaine.fr#ma-page
- Mauvaise URL : https://www.mondomaine.fr/categorie#mon-produit
- URL seo-friendly : https://www.mondomaine.fr/ma-page
Les développeurs Angular en PLS... Non mais plus sérieusement, il existe des solutions adaptées à votre framework JS pour vous guider dans la mise en place d'URLs "propres".
6. Vérifier les fichiers JS bloqués via votre robots.txt
Je ne vais pas m'attarder sur ce point, mais forcément, si vous empêchez le Googlebot d'accéder à vos fichiers JS, cela ne va jamais fonctionner :)
7. Javascript et lazy loading
Tout d'abord, très bien vu d'avoir implémenté du lazy loading. Ceci améliore l'expérience utilisateur et évite une surconsommation de ressources à l'ouverture de la page. Mais nous disions plus haut que Googlebot ne se comportait pas comme un navigateur normal. AInsi, il ne scroll pas. Il redimensionne constamment son viewport afin de capturer l'intégralité de votre page (en gros, il a un écran infini).
De cette façon, si pour déclencher l'affichage d'un média type image vous vous basez sur un événement type scroll, il y a de fortes chances que l'image ne soit jamais découverte par les robots des moteurs de recherche. Ce qui peut être dommageable si vous comptez notamment sur le SEO de vos images (pour référencer des produits ou une infographie par exemple).
À la place, vous pouvez utiliser le lazy loading natif des navigateurs.
8. Javascript et performance de chargement du site
On ne l'apprendra plus à personne, mais la performance de chargement d'un site internet va impacter :
- l'expérience utilisateur ;
- les ressources requises côté serveur et client ;
- votre crawl budget.
Par conséquent, il est nécessaire d'optimiser la façon dont vous "servez" vos fichiers en Javascript (comme on peut déjà le faire avec des fichiers CSS). Parmi ces méthodes on compte :
- la minimisation du JS ;
- le defering des ressources JS non critiques (donc pas core content) ;
- servir vos fichiers JS de manière plus frugale avec des payloads plus léger (technique du tree shaking par exemple) ;
- et l'inlining de votre JS.
Le SEO est une question d'excellence opérationnelle. Il faut être "parfait" notamment sur les bases. Dans le cadre de site en Javascript, cette discipline est d'autant plus requise. Nous avons pu observer des morceaux entiers de site ne pas être indexés dans Google à cause d'une simple erreur de code...

Javascript SEO : quelques questions
Question #1 : est-ce plus compliqué de faire du Javascript SEO ?
Non ! Les principes sont les mêmes, les tactiques aussi. La seule différence se fait sur la dimension technique qui est omniprésente et à considérer très régulièrement et dans une optique multidisciplinaire (développeurs + marketeurs).
Question #2 : est-ce que pour faire du Javascript SEO, il faut être développeur ?
Non. Néanmoins, le problème est le suivant : les marketeurs ne sont pas nécessairement suffisamment techniques pour le comprendre, et les développeurs ne sont pas nécessairement intéressés par le business pour penser SEO. Il faut donc que l'un des deux fasse le premier pas. Le Javascript SEO est amené à durer, parce qu'il permet de réaliser de nombreuses choses, il me paraît donc intéressant de s'y former (sans avoir besoin de devenir développeur). Et puis, le Javascript SEO s'appuie sur la mise en place "classique" des bonnes pratiques du SEO.
Question #3 : Wordpress versus site en Javascript ?
La question est volontairement maladroite. Wordpress est un CMS, Javascript est un langage de programmation. En fait, il ne faut pas opposer Wordpress à Javascript, mais plutôt opposer PHP à Javascript. Encore une fois, tout dépend de votre équipe technique et de vos contraintes. PHP est puissant, Javascript aussi. Pour un site vitrine, un PHP est largement suffisant. Pour une application web complexe, Javascript peut être une meilleure alternative.
Question #4 : Javascript et CMS ?
Il existe de nombreux CMS spécifiques à Javascript tels que Contentful ou Prismic par exemple. Ces CMS ne sont pas dédiés aux marketeurs et créateurs de contenus. C'est pourquoi ils sont généralement plus complexes à prendre en main que des CMS type Drupal, Wordpress, Shopify dont on a plus l'habitude.
A noter que comme ces CMS n'ont pas été initialement créés pour gérer un site riche en contenu, il leur manque nativement de nombreuses fonctionnalités que l'on retrouve pourtant dans des CMS gratuits type "Wordpress". Donc, veillez dans le déploiement de votre CMS headless type Contentful à vous assurer que vos développeurs embarquent :
- les méta données ;
- l' open graph et autres données structurées ;
- la possibilité d'avoir des arborescences (on parle de nesting d'URLs) type https://www.mondomaine.fr/categorie-1/sous-categorie/produit-2 ;
- la génération de sitemaps ;
- Le fichier robots.txt ;
- La gestion des médias type images (avec les bons formats WebP, JPG, SVG) et alt text ;
- et de nombreuses autres fonctionnalités.
Question #5 : donc tu es pro-Javascript pour le SEO ?
Non, mais je ne suis pas anti-Javascript non plus. C'est parce que je le connais et que je fais régulièrement des tests que je préfère un bon vieux PHP avec un Wordpress en CMS. Néanmoins, tout dépend de l'objectif du site internet. Il faut choisir le bon outil pour répondre à la bonne problématique, et parfois, l'utilisation du JS est parfaitement adéquate. Mais c'est justement parce que je connais les deux que je sais lequel choisir et comment les comparer.
Cependant, quand on arrive sur un projet "neuf", je préfère pousser un site vitrine sur un Wordpress "legacy", et la partie applicative de la web app sur un framework JS. Cela permet aux marketeurs de conserver leur autonomie pour la publication de contenus et le SEO, et aux développeurs de profiter de la flexibilité et de la puissance du JS sur la partie applicative souvent plus complexe.
N'hésite pas à consulter mes autres articles sur le Javascript SEO :
Newsletter
Les actus SEO & GEO chaque mois
Aucun spam. Les derniers insights directement dans votre boîte mail.
Questions fréquentes
Qu'est-ce que le Javascript SEO ?
Le Javascript SEO est une discipline du SEO Technique qui vise à optimiser les sites développés en Javascript afin de garantir leur accessibilité aux robots de recherche, de se conformer aux bonnes pratiques du SEO, de préserver l'internal linking, et de corriger les problèmes d'indexation et de positionnement sur Google de ce genre de sites et autres SPAs (Single Page Applications).
Pourquoi Google a du mal à comprendre les sites en Javascript ?
Cela vient en fait de la façon dont les moteurs de recherche (et en particulier Google) explorent et analyse le code d'un site en Javascript. En effet, le travail nécessaire par les "outils" des moteurs de recherche requiert plus de temps et de ressources. De fait, certains éléments d'un site internet en Javascript peuvent être négligés voire même jamais interprétés mettant ainsi en péril le positionnement de votre site.
Quelles sont les bonnes pratiques SEO pour un site en Javascript ?
Une question qui n'appelle pas une réponse courte. Mais en sus, (1) servez votre site en Server-Side, (2) balisez correctement vos liens internes (< a href>, (3) évitez les redirections Javascript, (4) pas de hash (#) dans vos URLs, (5) ne bloquez pas les ressources essentielles pour le rendering de votre site dans le fichier robots.txt, (6) testez régulièrement la crawlabilité de votre site en désactivant l'exécution du Javascript depuis votre navigateur, (8) et évitez de conditionner du lazy loading d'images à de l'interactivité (ex : scroll).






Partagez votre avis, vos questions, vos recommandations ci-dessous