Comment bloquer ChatGPT sur mon site ?

Ce qu'il faut retenir
EN RÉSUMÉ
La question centrale est celle du contrôle des contenus face aux IA génératives. L’article explique comment bloquer GPTBot et ChatGPT-User via le fichier robots.txt afin d’empêcher OpenAI d’explorer un site ou d’utiliser ses pages dans certaines réponses. Cette protection reste toutefois imparfaite : des contenus peuvent déjà avoir été collectés par OpenAI, Common Crawl ou d’autres sources utilisées pour entraîner des LLM. Au-delà de la technique, le sujet soulève un enjeu de rapport de force entre éditeurs, médias, sites commerciaux et plateformes d’IA, notamment autour de la citation, de la valeur créée et du recyclage des contenus.
OpenAI utilise plusieurs user agents, dont GPTBot et ChatGPT-User, pour explorer ou consulter des pages web.
Il est possible de bloquer ces robots via le fichier robots.txt, voire par IP, avec certaines limites.
Bloquer GPTBot n’empêche pas forcément que d’anciens contenus aient déjà été intégrés à des jeux d’entraînement.
La décision de bloquer ou non pose aussi une question stratégique et éthique autour de la valeur des contenus.
1h de coaching avec un expert
Réserver mon coaching
DÉBUT DE L'ARTICLE
Ce fut une des questions que j’ai le plus reçu quand j’ai écrit mon article sur comment fonctionnait ChatGPT et les prompts seo.
En effet, nous savons que ChatGPT peut utiliser votre site et vos contenus pour apprendre et donc fournir des réponses à d’autres individus par la suite.
Et cela s’explique par leur méthode d'entraînement. Les agents conversationnels tels que ChatGPT ou Bard de Google utilisent d’importantes quantités de données pour apprendre et être capable de répondre à vos prompts. C’est ce qu’on appelle des LLM (Large Language Models).
Et pour constituer ces LLMs, les géants du Web (OpenAI, Google, Opera, etc.) s’appuient sur des sources telles que des encyclopédies, Wikipedia, des livres numérisés, mais aussi les sites internet.
Empêcher ChatGPT de parcourir votre site
Depuis cet été 2023, le 09 Août pour être précis, OpenAI (l’entreprise mère derrière ChatGPT) a publié des directives pour pouvoir bloquer GPTBot en utilisant le fichier robots.txt.
GPTBot est le doux nom de user agent auquel répond le crawler d’OpenAI.
Petit rappel : un crawler est un robot d’exploration qui parcourt le web en utilisant les liens pour découvrir des pages et en “récupérer” le contenu. Une fois récupérés, ces contenus peuvent être “analysés” pour ensuite être indexés dans un moteur de recherche, ou être justement ajoutés à des LLM.
Et si vous voulez son nom complet, le voici :
- Identifiant court : GPTBot
- Identifiant complet : Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.0; +https://openai.com/gptbot)
Bloquer GPTBot en utilisant le fichier robots.txt
Maintenant que les connaissances sont faites, voici comment utiliser le fichier robots.txt pour bloquer GPTBot et empêcher qu’il n’explore votre site internet :
User-agent: GPTBot
Disallow: /
Plus largement, GPTBot répond aux directives d’utilisation des fichiers robots.txt. Vous pouvez donc lui autoriser certaines parties du site et le bloquer sur d’autres :
User-agent: GPTBot
Allow: /fiche-produit/
Disallow: /blog/
Vous pouvez aussi contraindre GPTBot en bloquant via le fichier HTAccess les adresses IP qu’il utilise pour l’exploration (en voici la liste au 24 Octobre) :
- 20.15.240.64/28
- 20.15.240.80/28
- 20.15.240.96/28
- 20.15.240.176/28
- 20.15.241.0/28
- 20.15.242.128/28
- 20.15.242.144/28
- 20.15.242.192/28
- 40.83.2.64/28
- 20.9.164.0/24
- 52.230.152.0/24
Néanmoins, gardez en tête que ces adresses IP peuvent être modifiées ou que de nouvelles peuvent être ajoutées (en un mois et demi, il y en a eu deux de plus). Vous pouvez retrouver la liste officielle ici : https://openai.com/gptbot.json
Empêcher ChatGPT-User de parcourir votre site
Comme vous le savez sûrement, ChatGPT embarque depuis Mars 2023 des plugins. Ces plugins, permettent à un utilisateur de ChatGPT de lui ordonner de naviguer sur une page web précise. C’est alors que le user agent ChatGPT-User s’exécute et va naviguer sur la page web précisée par l’utilisateur.
Concrètement, si un utilisateur écrit un prompt tel que “ Fais-moi un résumé de l’article Comprendre les critères EEAT de Google et son impact sur le SEO ” en indiquant le lien, ChatGPT va utiliser le bot ChatGPT-User pour accéder à ma page web et récupérer mon contenu pour le résumer…
Si vous ne souhaitez pas que ce genre de choses vous arrive, vous pouvez alors empêcher ChatGPT-User d’accéder à votre site grâce à votre fichier robots.txt
User-agent: ChatGPT-User
Disallow: /
Voici d’ailleurs l’identité complète du “coupable” :
- Identifiant court : ChatGPT-User
- Identifiant complet : Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; ChatGPT-User/1.0; +https://openai.com/bot
Alors, tout comme GPTBot, ce second user agent d’OpenAI répond à l’ensemble des directives robots.txt. Vous pouvez donc moduler ses “accès” :
User-agent: ChatGPT-User
Disallow: /blog/
Allow: /forum/
Et voici, à date, l’unique adresse IP utilisée par ChatGPT-User : 23.98.142.176/28
Bloquer GPTBot et ChatGPT-User avec le fichier robots.txt
Alors sachez qu’il n’est pas nécessaire de bloquer les deux user agents (ChatGPT-User et GPTBot) séparément. Si vous bloquez l’un des deux, ça bloquera automatiquement le second. Je cite :
Our opt-out system currently treats both user agents the same, so any robots.txt disallow for one agent will cover both.
Si vous n’êtes pas familier de la langue de Shakespeare, OpenAI déclare qu’aujourd’hui leur système de “désinscription” traite les deux user agents de la même manière. C’est à dire que si l’un des user agents est bloqué dans le fichier robots.txt, la directive s’appliquera aux deux user agents.
Alors, c'est vrai aujourd'hui. Est-ce que cela le sera dans quelques mois ? Qui sait. Je vous conseillerai ainsi de bloquer les deux.
Quelle différence entre GPTBot et ChatGPT-User ?
Chacun de ces deux user agents répond à des besoins différents d’OpenAI et de ChatGPT.
GPTBot est un robot d’exploration qui explore le web en autonomie, en suivant les liens de pages web en pages web, de domaines en domaines, et en “récupérant” le contenu (le DOM pour être plus précis) de chaque page web visitée. Son fonctionnement est similaire aux robots d’exploration des moteurs de recherche.
L’objectif de GPTBot est de récupérer des contenus qui vont permettre d’améliorer les futurs modèles d’entraînement des intelligences artificielles d’OpenAI.
ChatGPT-User est un robot qui ne s’exécute que sur demande d’un utilisateur de ChatGPT. Une fois qu’il s’est rendu sur la page web indiqué par l’utilisateur, il utilise le contenu de cette page web pour formuler une réponse au prompt de l’utilisateur.
Peut-on réellement empêcher ChatGPT d’utiliser nos contenus ?
Oui et non. Et avant de me faire lyncher pour cette réponse de Normand, permettez-moi de m’expliquer.
Oui dans la mesure où si vous bloquez GPTBot, normalement, ce user agent d’OpenAI ne pourra accéder à votre site pour en récupérer les contenus afin de nourrir son LLM.
Non, et pour deux raisons :
La première est que votre site aurait déjà pu être visité par GPTBot (et aussi par ChatGPT-User). Si c’est le cas, il est fort à parier que votre contenu ait déjà intégré un LLM (sous certains critères car ils sont censés filtrer certains types de contenus ou les contenus payants par exemple).
La seconde est sûrement plus probable. Comme je le disais en introduction, les LLMs des intelligences artificielles sont composés de larges jeux de données qui incluent de multiples contenus. Le concept même de “robots d’exploration” du web ne date pas de ChatGPT mais remonte aux années 90.
Ainsi, depuis plusieurs années, des robots d’exploration agrègent des contenus qu’ils trouvent sur la toile. Et parmi ceux-là, on compte notamment WebText2 et Common Crawl.Ce sont notamment ces deux robots d’exploration qui ont contribué à la création des LLM utilisés par la version GPT3.0 et GPT3.5 de ChatGPT. Donc il est fort probable, qu’avant même l’arrivée de ChatGPT, votre contenu web fût déjà exploré voire intégré dans des LLMs pour entraîner des intelligences artificielles.
A noter donc, qu’en plus des user agents d’OpenAI, il faudrait bloquer aussi celui de Common Crawl, ce qui est possible.
En conclusion, si vous bloquez dès aujourd’hui l’ensemble des user agents utilisés par OpenAI pour constituer ses LLM, vos futurs contenus ne devraient normalement pas être utilisés. La question subsidiaire néanmoins est : connaissons-nous l’ensemble des user agents utilisés par OpenAI pour constituer ses dataset d’entraînement ? Je n’ai pas la réponse concernant GPT4.0 qui est la nouvelle version de ChatGPT.
Pourquoi bloquer GPTBot et ChatGPT-User ?
Voilà une excellente question. Compte tenu du fait que nous sommes encore qu’au prémisse des champs d’application de ces intelligences artificielles, je ne vois pas forcément de risques à les bloquer. Certains évoqueront une pénalité dans les résultats de recherche des moteurs de recherche Bing et Google, mais je ne pense pas. Du moins, pas au début.
Un rapport de force déséquilibré entre éditeurs et intelligence artificielle
Le sujet est aussi éthique.
En effet, les agents conversationnels tels que ChatGPT (hors plugin) et Bard ne citent jamais les auteurs ou les sources à partir desquels ils ont obtenu leur réponse. Ainsi, ils n’apportent aucune valeur aux médias dont le business model repose sur le nombre de pages vues et d’impressions sur les publicités.
Ils n’apportent aussi aucune valeur au blog d’une agence web qui utilise le SEO pour obtenir des prospects. Ou au SaaS qui le faisait dans le même objectif.
Alors, puisque OpenAI, Google, et bien d’autres profitent du contenu des éditeurs pour entraîner leurs intelligences artificielles, ne serait-ce pas normal d’avoir un système de opt-in / opt-out entre les sites internet et les entreprises d’IA ?
Qui plus est, quand on voit aussi que ChatGPT Plugin facilite énormément la paraphrase du contenu d’autrui, nous exposons nos contenus au recyclage (plus particulièrement au spinning) et à la publication en masse sans citation…
Les médias d’autorité qui bloquent GPTBot et/ou ChatGPT-User
Ce sont clairement les “gros” médias d’informations qui souffrent les premiers de ce nouveau genre d’outils. Eux dont le business model repose essentiellement sur la visite de leur site internet pour “vendre” des impressions de publicité ou des abonnements.
Ainsi, je me suis intéressé à leur comportement vis-à-vis du blocage des user agents de OpenAI. Nous retrouvons en effet des médias tels que le Financial Times, le New-York Times, Bloomberg, The Guardian, et en France Libération, le Figaro, le Point, et sûrement de nombreux autres qui ont bloqué au moins un user agent d’OpenAI.
Quelques exemples ci-dessous :
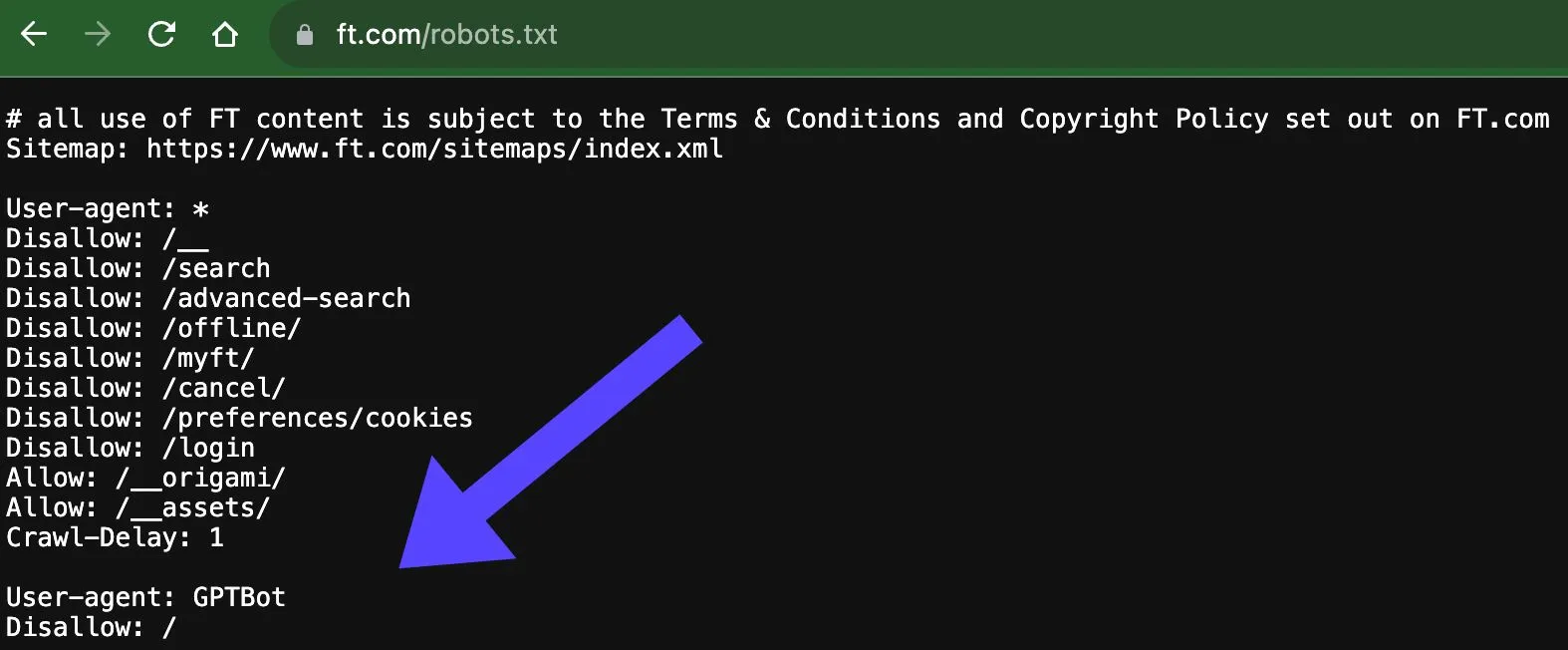
Financial Times qui bloque GPTBot :
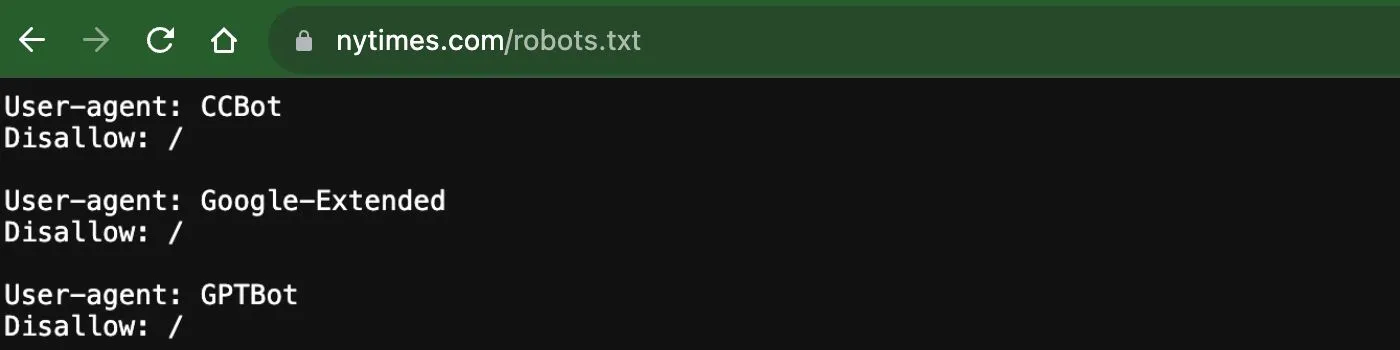
Le New York Times qui fait la triplette CCBot (Common Crawls), Google-Extended (Bard), et GPTBot :
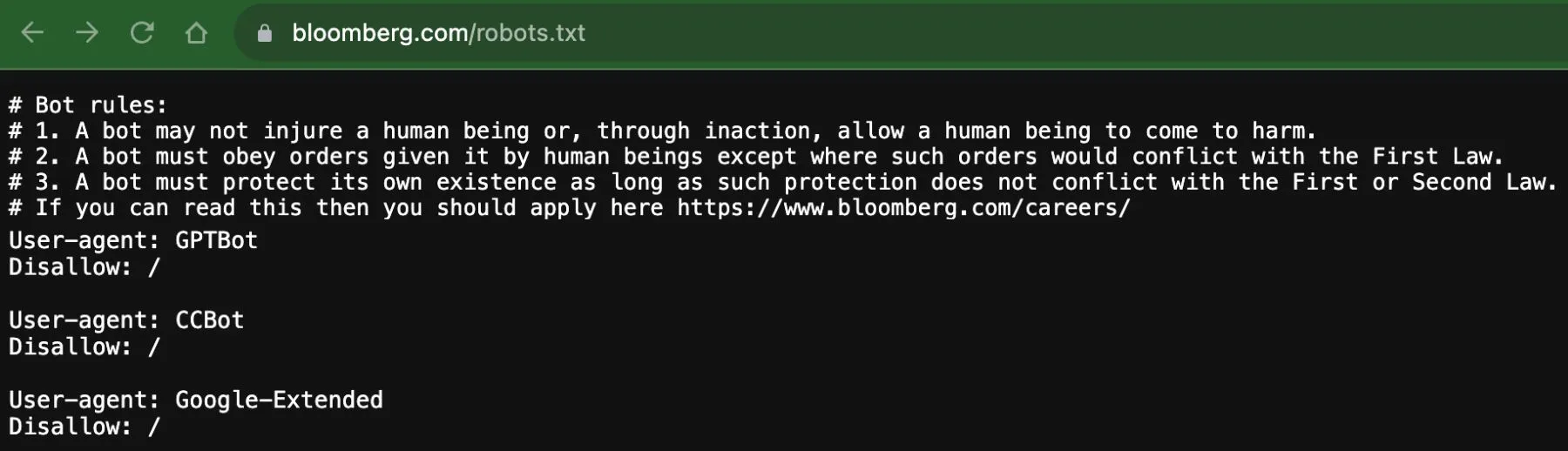
Bloomberg qui se permet au passage de rappeler les 3 lois de la robotique :
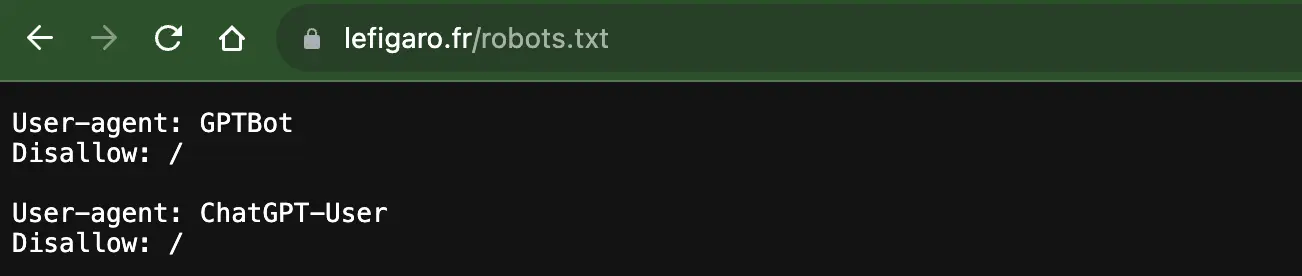
Le Figaro qui par mesure de sécurité a décidé de bloquer les deux user agents d’OpenAI :
Libération :
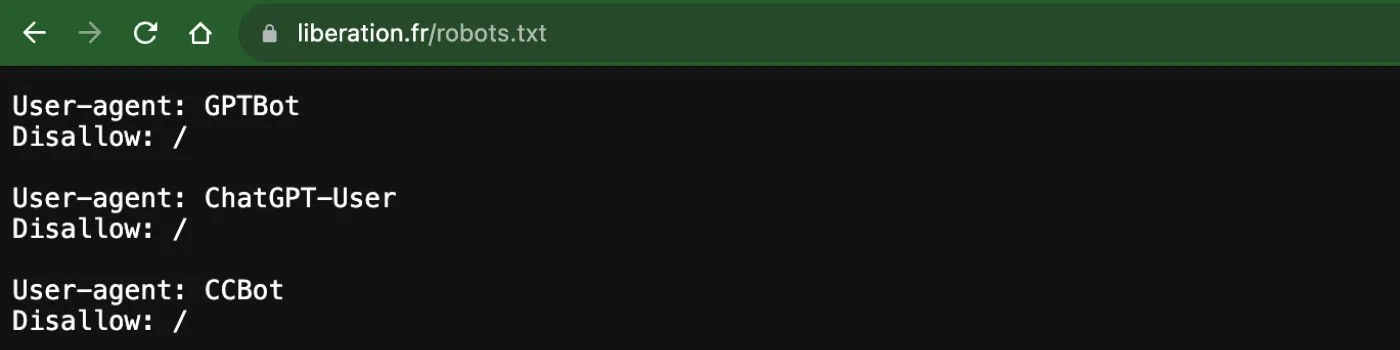
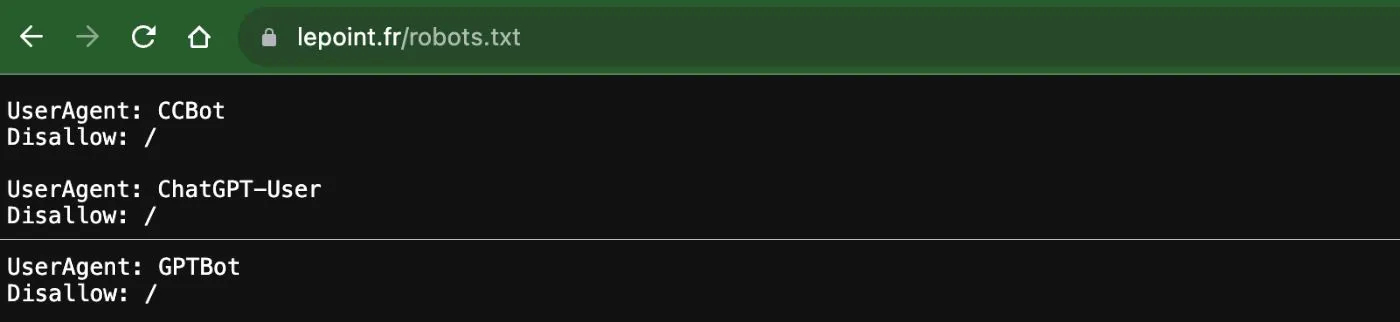
Le Point :
Nous retrouvons aussi des sites “commerciaux” tels que Amazon, AirBnB, Coursera, et j’en passe.
Amazon.fr par exemple :

Si la curiosité vous prend, vous n’avez qu’à ajouter “/robots.txt” à la fin du nom de domaine d’un site internet pour avoir accès au fichier robots.txt et chercher un des user agents mentionnés.
En résumé
Oui, il est possible de bloquer les user agents d’OpenAI et donc d’empêcher ChatGPT d’avoir accès à vos contenus actuels et futurs (à condition qu’ils n’aient pas déjà été “explorés”).
Mais on manque encore de transparence : nous ne disposons pas d’une liste exhaustive des robots utilisés par OpenAI. Par exemple, Common Crawl et son user agent CCBot ne sont pas opérés par OpenAI, mais leurs données sont bel et bien exploitées dans l’entraînement de ses modèles.
Autrement dit, bloquer uniquement ChatGPT-User, GPTBot et CCBot ne vous garantit pas que vos contenus ne seront jamais utilisés.
Il faut aussi relativiser : la force d’un LLM, c’est de combiner des milliards de points de données. Le contenu d’un seul site web, aussi qualitatif soit-il, n’est souvent qu’une brique dans cet océan. Marmiton pourrait bloquer ses recettes… ChatGPT continuerait à vous proposer une pâte à crêpes.
Cela étant dit, on comprend très bien pourquoi des groupes média ou des acteurs du contenu à forte valeur ajoutée choisissent de bloquer l’accès à leurs pages. La perspective de voir une IA générer des dépêches ou des articles sans les citer ni trianguler l’information pose de vrais enjeux.
Mais à l’inverse, il faut aussi envisager des cas où l’ouverture à ces robots pourrait servir la visibilité. Un site e-commerce, par exemple, pourrait voir son catalogue intégré dans une réponse générative enrichie sur Bing. Et là, le GEO (Generative Engine Optimization) entre en jeu. Car oui, un contenu bien structuré, clair et fiable peut — dans certains cas — être réutilisé par une IA au bénéfice de votre marque. J’en parle plus en détail mon article sur le Generative Engine Optimization (GEO).
Newsletter
Les actus SEO & GEO chaque mois
Aucun spam. Les derniers insights directement dans votre boîte mail.
Questions fréquentes
Comment empêcher ChatGPT d'utiliser le contenu de mon site ?
Vous pouvez empêcher l'un des deux (voire les deux) user agents de ChatGPT d'accéder l'ensemble ou partie de votre site en utilisant les directives du robots.txt. Pour cela, il vous suffit de rajouter le nom du user agent d'un des deux robots utilisé par ChatGPT (GPTBot ou ChatGPT-User) et à la ligne en-dessous rajouter la directive "Disallow : /"
Quelle est la différence entre GPTBot et ChatGPT-User ?
Ces deux user agents qu'OpenAI utilise pour ChatGPT ont effectivement deux fonctions bien différentes. GPTBot explore automatiquement l'ensemble du site afin de récupérer des contenus qui pourraient enrichir les modèles de données qui servent à entraîner leurs intelligences artificielles. ChatGPT-User repose seulement sur ChatGPT Plugin et peut accéder à une page web précise que sur "ordre" d'un utilisateur de ChatGPT puis se servir du contenu de cette page web pour répondre au prompt de l'utilisateur.
Pourquoi bloquer ChatGPT sur son site ?
Afin d'éviter que vos contenus "frais" puissent être instantanément repris, paraphrasés, formatés, et republiés sans même vous citer. On observe en effet de plus en plus de médias (Libération, le Figaro, New York Times, The Guardian) qui bloquent effectivement les user agent d'OpenAI (GPTBot et ChatGPT-User) mais aussi celui de Common Crawl (CCBot) sûrement à ces fins. A noter aussi que des sites marchands s'y prêtent aussi : Amazon, AirBnB, Coursera, et des milliers d'autres.







Partagez votre avis, vos questions, vos recommandations ci-dessous