Query Fan Out : Sous le capot de la décomposition des requêtes en GEO

Ce qu'il faut retenir
EN RÉSUMÉ
Avec le Query Fan Out, une requête n’est plus une instruction figée, mais un signal que l’IA interprète, enrichit et décompose pour produire une réponse utile. Le système projette des intentions latentes, génère des sous-requêtes, identifie les sources et formats les plus efficaces, puis sélectionne quelques fragments capables d’alimenter la réponse finale. Cette logique transforme la création de contenu : il faut produire des blocs granulaires, structurés, multimodaux et autonomes, pensés pour être lus, mais aussi récupérés, comparés, recombinés et cités par les IA.
Le Query Fan Out transforme une requête initiale en plusieurs sous-requêtes explicites, implicites et contextuelles.
Les moteurs génératifs ne cherchent pas une page unique, mais la réponse la plus probable de satisfaire l’utilisateur.
En GEO, le contenu doit anticiper les intentions latentes, les formats attendus et les différentes modalités de réponse.
Pour être cité, un fragment doit être pertinent, dense, fiable, récent si nécessaire et facilement exploitable par l’IA.
1h de coaching avec un expert
Réserver mon coaching
DÉBUT DE L'ARTICLE
Le Query Fan Out est une brique élémentaire du GEO (Generative Engine Optimization). Pour faire simple, c'est la manière dont un agent conversationnel "digère" votre question avant même de commencer à chercher une réponse.
Dans ce nouveau paradigme, l'IA ne traite plus votre input (requête) comme une instruction unique, mais comme un signal de départ.
Cette requête est alors décomposée en une multitude de sous-requêtes, explicites ou implicites, afin de couvrir l’ensemble des besoins informationnels nécessaires à la production d’une réponse complète, cohérente et utile.
Autrement dit, la requête saisie par l’utilisateur n’est plus qu’un point de départ, et non l’instruction réellement exploitée par le système.
Prenons un exemple simple. Si je pose la question : “Que faire à Florence ?”, une IA générative ne va pas chercher une seule page capable de répondre à cette question. Elle va projeter une série de sous-requêtes, parmi lesquelles :
- Les incontournables à Florence ;
- Les meilleurs musées de Florence ;
- Les monuments historiques à visiter ;
- Que faire à Florence en 2 ou 3 jours ;
- Quartiers à visiter à Florence ;
- Activités gratuites ou en plein air à Florence ;
- Meilleure période pour visiter Florence ;
- Que visiter à Florence sous la pluie.
Certaines de ces sous-requêtes correspondent à des intentions évidentes. D’autres sont anticipées par le système, car elles apparaissent régulièrement dans des parcours utilisateurs similaires (ce qui veut dire qu’on peut aussi influencer une IA si celle-ci se base sur les comportements d’autres utilisateurs, mais je traiterai ceci une autre fois).
C’est cette “explosion” contrôlée de la requête initiale que l’on appelle le Query Fan Out.
La requête n’est plus une instruction. C’est un point de départ pour explorer un espace d’intentions.
Et c’est précisément ce mécanisme qui change profondément la manière dont il faut penser le contenu en GEO.
Dans la suite de cet article, je vais donc détailler le fonctionnement du Query Fan Out et expliquer ce qui se passe réellement « sous le capot », si vous me passez l’expression.
Je n’ai évidemment pas la documentation interne de Google Gemini ou d’OpenAI. Mais nous avons deux choses : (1) la littérature IR/RAG, (2) l’observation des outputs (résultats).
Comprendre ces fondations est indispensable pour bâtir des stratégies solides et, surtout, pour conserver une longueur d’avance dans un écosystème en perpétuelle évolution.
Je reste convaincu qu’il n’existe pas de raccourci durable. Les promesses de recettes rapides et de hacks miracles masquent bien souvent une compréhension superficielle — voire erronée — des systèmes. Or, sans maîtrise des mécanismes fondamentaux, aucune stratégie ne tient dans le temps.
Avant d’aller plus loin : la nature probabiliste des réponses IA
Le Query Fan Out n’est pas une simple expansion de requête. Il s’agit d’un mécanisme bien plus complexe. Une IA générative ne cherche pas la réponse unique ; elle sélectionne la réponse la plus probable d’être la meilleure, compte tenu du contexte, des sources disponibles et de ses propres contraintes.
Vous pourriez me répondre : « Jusqu’ici, Quentin, c’est aussi le cas d’une recherche classique sur un moteur comme Google. »
Et vous auriez raison — dans une certaine mesure. Tout moteur dont le modèle économique repose sur la rétention de l’utilisateur cherche avant tout à lui apporter satisfaction.
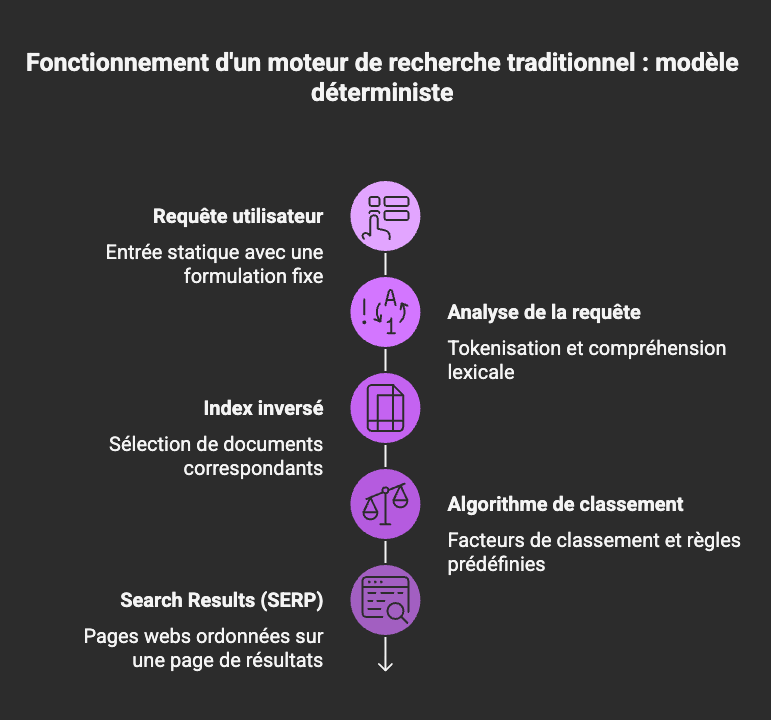
Répondre à une requête : modèle déterministe vs. modèle probabiliste
Les moteurs de recherche traditionnels fonctionnent principalement selon un modèle déterministe qui fonctionne comme suit (de manière simplifiée) :
- l’utilisateur effectue une recherche ;
- le moteur commence par analyser la requête (tokenisation, compréhension lexicale) ;
- le moteur recherche ensuite dans son index inversé les documents correspondants ;
- les documents sélectionnés sont ensuite traités par un algorithme de classement, qui applique un ensemble de critères de pertinence (les fameux ranking factors) et de pondérations prédéfinies pour les ordonner et produire une page de résultats ;
- l’utilisateur voit s’afficher plusieurs liens vers des pages qui correspondent normalement à sa requête.
Dans ce modèle déterministe, la requête initiale est relativement statique : elle constitue le point d’entrée principal du système et conditionne fortement le résultat de la recherche. Le moteur cherche alors à identifier et classer les documents qui correspondent le mieux à cette requête, selon des règles connues du système.
À l’inverse, les moteurs de recherche génératifs reposent sur des modèles probabilistes. Leur objectif n’est pas de déterminer la meilleure page pour une requête donnée, mais de produire la réponse la plus susceptible (probable) de satisfaire l’utilisateur, en tenant compte non seulement de la requête, mais aussi du contexte, de l’historique de l’échange et des sources de données disponibles.
Prenons un exemple simple. Si vous posez la question : « Quelle est la meilleure ville de France ? », une IA générative ne peut pas se contenter d’une réponse unique et universelle. Elle va d’abord chercher à interpréter le contexte implicite de la question : avez-vous évoqué la gastronomie auparavant ? Les plages ? La qualité de vie familiale ? Les opportunités professionnelles ?
En fonction de ces signaux contextuels, le système va alors attribuer des scores de probabilité à différentes réponses possibles, avant de formuler celle qui a la plus forte probabilité d’être perçue comme pertinente dans ce contexte précis.
Ainsi, l’IA ne va pas simplement chercher une réponse ou un document, il itère sur les interprétations possibles de votre requête, jusqu’à identifier celle qui maximise la probabilité de satisfaction dans un contexte donné.
L’IA ne cherche pas la bonne réponse. Elle cherche la réponse la plus probable.
Cette nature probabiliste a une conséquence directe : le système ne peut plus se contenter d’une interprétation unique de la requête.
Face à une question ouverte, ambiguë ou contextuelle, il doit envisager plusieurs hypothèses possibles sur ce que l’utilisateur cherche réellement à savoir.
Or, pour évaluer ces hypothèses, le moteur n’a pas d’autre choix que de les transformer en besoins informationnels distincts, chacun nécessitant d’aller chercher des éléments de réponse spécifiques.
C’est précisément à ce moment-là que la requête initiale cesse d’être une instruction unique, et devient le point de départ d’un processus de décomposition.
Ce processus constitue le socle opérationnel du Query Fan Out.
Pour tester plusieurs hypothèses, le système doit les transformer en requêtes. C’est exactement ce que permet le Query Fan Out.
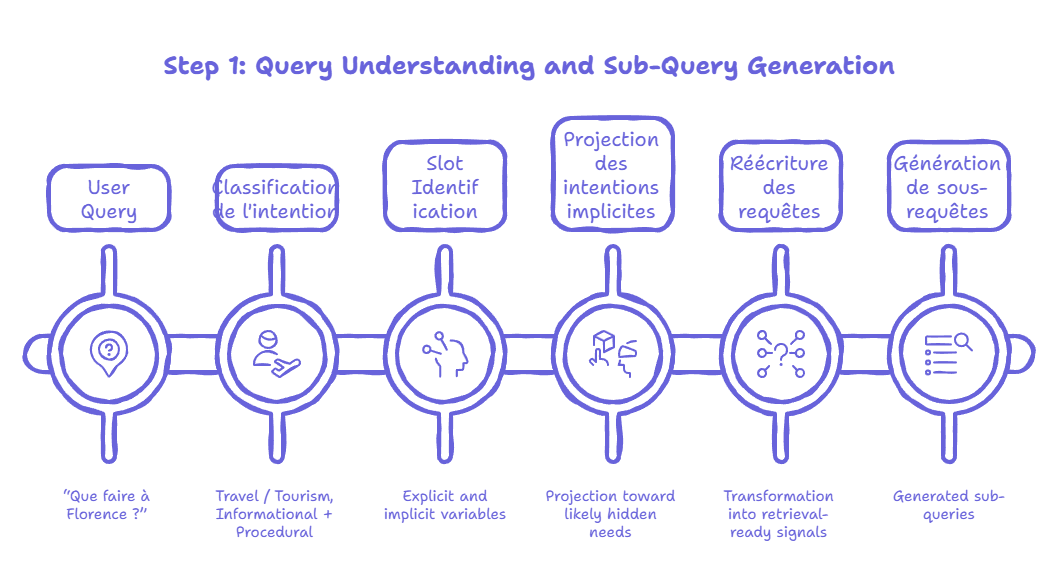
Étape #1 : Expansion de requête (Query Fan Out)
C’est ici que le système passe de l’interprétation à la génération d’hypothèses.
Reprenons notre exemple du début et imaginons que vous demandiez à ChatGPT “Que faire à Florence ?”. Si sa première réponse était “manger des pizzas” ou “visiter des musées”, je pense que cela ne répondrait pas nécessairement à votre besoin.
La première étape pour l’IA consiste donc à “enrichir” votre requête initiale pour parvenir à une requête plus aboutie, plus complète, bref, plus probable de vous satisfaire.
Classification de l’intention = cadre de réflexion
La première étape consiste à définir le périmètre de la recherche. Contrairement au SEO classique qui cherche à "étiqueter" un mot-clé, l'IA s'appuie sur des architectures de compréhension sémantique profonde (Chen et al., 2019) pour cartographier un besoin. C’est ce diagnostic qui va piloter l'ampleur du Query Fan Out.
Sur une requête comme “Que faire à Florence ?”, le système opère une décomposition multidimensionnelle :
Lorsque vous la donnez à un moteur génératif, il va normalement la décomposer de la manière suivante :
- domain identification : le modèle classe la requête dans une ontologie (Voyage > Europe > Italie). Cela permet d'activer les vecteurs sémantiques les plus pertinents pour ce domaine précis (faire appel à un index "Voyage" et non "Recette de cuisine") ;
- intent detection : le système détecte ici une intention hybride : informationnelle (découvrir) et procédurale (organiser). Cette dualité force l'IA à générer des sous-requêtes variées, allant de l'histoire de l'art à la logistique des transports. Les intentions peuvent être variées : informationnelle, procédurale, commerciale, transactionnelle, générative, et navigationnelle. C’est aussi une différence avec le SEO où on cherche une intention, là où l’IA peut en détecter (ou en faire l'hypothèse) de plusieurs simultanément.
- Risk/Safety Profile : le système évalue la sensibilité de la question (similaire au concept YMYL - Your Money Your Life). Pour un conseil médical, le Query Fan Out se "verrouillerait" sur des sources expertes. Pour Florence, le profil de risque est faible, ce qui autorise une exploration plus large et créative des sources.
Cette phase de diagnostic initial, qui s'appuie sur des architectures de compréhension sémantique profonde (Chen et al., 2019), est ce qui va piloter l'ampleur du Query Fan Out. Le système identifie si la tâche est informationnelle ou procédurale pour savoir quel index mobiliser.
Slot Identification : Extraire les variables de l’intention
En parallèle de la classification globale, le système procède à une analyse granulaire appelée Slot Filling. Cette étape, cruciale pour stabiliser le contexte de la recherche, consiste à extraire les entités et les contraintes spécifiques de votre phrase pour remplir des "cases" d'informations (Kuratov et al., 2019).
Ces deux processus s'auto-alimentent : identifier le slot "Florence" confirme le domaine "Voyage", et vice-versa. Pour notre exemple, l'IA identifie instantanément les segments porteurs de sens, appelés Explicit Slots :
- Lieu (location) : Florence.
- Action (activity) : "Que faire".
C'est cette identification qui permet au système de savoir quels paramètres doivent être précisés avant de lancer l'explosion de requêtes. Si vous aviez ajouté "en 3 jours", le slot duration (durée) aurait été activé, forçant le Fan Out à chercher des itinéraires temporels plutôt que de simples listes de monuments.
Mais la puissance du Query Fan Out réside surtout dans sa capacité à identifier des Implicit Slots (slots implicites) : des variables que vous n'avez pas nommées, mais que l'IA déduit pour rendre sa réponse utile et statistiquement probable.
Vous ne répondez plus à une question. Vous répondez à un ensemble de variables.
Projection des intentions implicites (implicit intent projection) : Prédire l'implicite
Jusqu’à maintenant, l’IA n’a fait qu’uniquement “interpréter” notre requête initiale. Mais c’est à partir de cette étape qu’elle commence à se “projeter”.
C'est ici que la nature probabiliste de l'IA prend tout son sens : le moteur projette votre requête dans un espace vectoriel pour identifier les intentions "fantômes” ou “voisines” qui y sont statistiquement liées. Et pour ce faire, elle peut utiliser des knowledge graphs, des données historiques, etc.
Si je repars toujours de notre exemple “Que faire à Florence ?”, l’IA va projeter ma requête sur des besoins implicites qu’elle a identifié grâce à la vectorisation et à son index :
- projection logistique : “Comment se déplacer dans le centre historique ?”
- projection temporelle : “Quels sont les horaires de la Galerie des Offices (Galerie Uffizi) ?”
- projection de confort : “Où trouver les meilleurs points de vue sans avoir trop de foule ?”
C’est cette capacité de projection qui détermine une partie de la stratégie de réponse et rend la réponse de l’IA généralement plus complète et satisfaisante qu’une simple recherche sur un moteur de recherche déterministe.
Ce que l’utilisateur ne dit pas devient souvent plus important que ce qu’il a dit.
Réécriture de requêtes (query rewriting) : Traduire la projection en signal
Une fois les intentions latentes projetées, le système doit les concrétiser. C’est le rôle du Query Rewriting (Ma et al., 2023) : une véritable traduction technique qui transforme vos pensées en signaux exploitables par l'algorithme de récupération (le Retriever).
Dans cette phase, l'IA ne se contente pas de chercher des synonymes. Elle effectue un double ajustement :
- L'optimisation sémantique : Elle transforme une question naturelle, fluide mais parfois floue, en une suite de mots-clés techniques et de descripteurs sémantiques. C'est le passage d'une recherche textuelle classique à une recherche vectorielle, où l'IA cherche des "concepts" plutôt que de simples mots.
- L'adaptation au format de réponse : Si l'IA projette que la meilleure réponse à votre besoin est un itinéraire structuré, elle va "forcer" la recherche vers des types de documents spécifiques.
C’est pourquoi, derrière une simple question sur Florence, le système génère en réalité des requêtes chirurgicales : certaines resserrent le contexte (“Que faire à Florence en 3 jours en mars”), tandis que d’autres ciblent des formats de données précis (“Plan de voyage PDF weekend 3 jours Florence” ou “tableur budget voyage Toscane”).
Ce mécanisme garantit que la réponse finale ne sera pas seulement exacte, mais surtout opérationnelle, en allant chercher l'information là où elle est la plus structurée.
Résumé :
En résumé, ce qu'il faut retenir de cette phase de Query Fan Out, c'est que l'IA ne prend pas votre requête comme une instruction figée : elle l'interprète, l'extrapole et la décompose (Ammann et al., 2025) pour générer une réponse statistiquement susceptible de vous satisfaire.
Votre requête initiale n’est que le signal de départ d'une matrice complexe d'intentions explicites et latentes. Si vous créez du contenu uniquement pour adresser la question de surface, vous ne vous positionnez que sur une seule "branche" d'un arbre décisionnel beaucoup plus vaste.
En termes de création de contenus, cela implique deux changements majeurs :
- L'exhaustivité contextuelle : Ne répondez pas juste au "quoi", mais anticipez le "comment", le "pour qui" et le "et après ?".
- La précision granulaire : Puisque l'IA fragmente sa recherche (Zhou et al., 2022), votre contenu doit être structuré pour adresser plusieurs "sous-requêtes" de manière chirurgicale au sein d'une même page.
Sources pour l’étape #1 :
- Chen, Q., et al. (2019). BERT for Joint Intent Classification and Slot Filling.
- Kuratov, Y., et al. (2019). Joint Intent Classification and Slot Filling.
- Ma, X., et al. (2023). Query Rewriting for Retrieval-Augmented Large Language Models.
- Ammann, J., et al. (2025). Question Decomposition for Retrieval-Augmented Generation. Note : C'est la base théorique du "Fan Out" : comment une question unique est fragmentée en sous-problèmes plus simples et factuels.
- Zhou, D., et al. (2022). Least-to-Most Prompting Enables Complex Reasoning in Large Language Models.
Étape #2 : Détermination des sources et des modalités
À l’étape précédente, l’IA est partie de votre requête initiale pour générer des dizaines si ce n'est des centaines de requêtes qui correspondent à votre intention de recherche initiale, mais adressent aussi des dimensions (slots) complémentaires, et qui sont souvent plus précises.
Ainsi, chacune de ces “sous-requêtes” devient donc une tâche à exécuter et pour chaque tâche, le système doit déterminer :
- Quelles sources utiliser ?
- Quel format de réponse est le plus approprié ?
- Quelle méthode de récupération est la plus efficace ?
Et c’est justement en comprenant comment le système adresse ses questions que vous pouvez créer un contenu susceptible d’être cité par une IA.
Détermination des sources
C'est ici que l'IA projette ce que l'on appelle la Preferred Modality (la forme de réponse la plus efficace pour l'utilisateur). C’est-à-dire que pour chaque tâche, l’IA identifie la bonne source et le bon format.
Repartant de ma requête “Que faire à Florence ?” et imaginons que celle-ci a généré les sous-requêtes suivantes :
- Top 5 hôtels romantiques à Florence ;
- Incontournables Florence centre historique à pied 1 jour ;
- Coupe-file Galerie des Offices réservation immédiate ;
- Street food typique Florence pas cher (Lampredotto) ;
- Marchés couverts Florence (Mercato Centrale) horaires.
Chacune de ces requêtes à des caractéristiques différentes. Par exemple, la requête “Top 5 hôtels romantiques” sera probablement adressée à partir des avis déposés sur des sites de réservation et peut-être de quelques blogs de voyageurs. Le format de réponse sera probablement représenté par un tableau avec des images des chambres ; Les incontournables à faire à pied en 1 jour peut être une image avec un plan simplifié et qui agrège les informations récupérées de plusieurs blogueurs.
Si vous vous demandez comment l'IA sait qu'une vidéo est préférable à un texte pour du Street Food, la réponse tient en deux piliers :
- L'historique de performance (Feedback Loop) : Le système maintient un mapping interne basé sur les données de performance passées. Si, par le passé, extraire un "Plan" d'un blog expert a généré une meilleure satisfaction utilisateur qu'un texte brut, ce type de source sera systématiquement favorisé pour cette classe de requête.
- La Modalité comme cible de récupération (Retrieval Target) : Ce n'est pas un hasard. La modalité est traitée comme une spécification de recherche dès le départ. Si l'IA décide qu'une tâche "Routine" (comme notre street-food) nécessite du visuel, elle va interroger prioritairement des index optimisés pour la vidéo.
Vous comprenez donc l'enjeu : pour être cité, votre contenu doit non seulement répondre à l'intention, mais il doit aussi adopter le format que l'IA a déjà "préparé" pour sa réponse.
Réalisme économique et arbitrage technique
Ce déploiement de moyens n'est pas illimité. À partir d’une requête, l’IA peut en générer des centaines, chacune nécessitant une action de retrieval coûteuse en énergie et en calcul. Comme le rappelait Sam Altman (OpenAI), chaque interaction a un coût.
Solliciter des API externes, vectoriser des bases de données de vidéos ou effectuer des recherches web massives pèse sur le bilan économique du moteur. Par conséquent, l’IA ne déploie pas toute son "armada" pour chaque question :
- Priorisation par importance : Le système adapte ses efforts selon le niveau d'importance ressenti de la requête (une question médicale vs une simple curiosité).
- Efficience du format : L'IA privilégiera toujours les formats faciles à segmenter (chunking) et à intégrer, comme les transcriptions textuelles plutôt que l'analyse brute d'un fichier vidéo lourd.
L’enjeu pour vous : Pour être cité, votre contenu doit non seulement répondre à l'intention, mais adopter le format le plus "économique" et efficace pour l'IA. Si vous compliquez l'extraction de l'information (format propriétaire, texte noyé), vous augmentez son coût de traitement, et donc le risque d'être ignoré.
Résumé : Le GEO est une bataille de formats
Du point de vue du GEO (Generative Engine Optimization), l'étape du routing est le moment où tout se gagne ou se perd. Si votre contenu ne correspond pas à la modalité (le format) attendue par le système pour une sous-requête donnée, il a de fortes chances de ne jamais être extrait, quelle que soit sa qualité intrinsèque.
C'est ici qu'intervient la notion de parité multimodale :
- Multipliez les représentations : Si vous publiez un itinéraire sur Florence, il doit exister sous forme de texte narratif, de tableau structuré, d'image (plan) et idéalement d'une courte vidéo avec sa transcription.
- Optimisez l'accessibilité technique : Assurez-vous que vos données sont "faciles à découper" (chunking) pour l'IA. Préférez les tableaux HTML aux PDF et proposez des transcriptions horodatées pour vos vidéos afin de faciliter leur indexation textuelle.
- Alignez-vous sur le profil de routage : Plus votre contenu s'aligne sur les formats privilégiés par l'IA (le "moule" projeté), plus il a de chances d'être récupéré sur plusieurs branches simultanées du Fan Out.
En résumé : Ne vous contentez pas d'écrire pour être lu, structurez pour être récupéré.
Étape #3 : Sélection finale des résultats
Une fois la phase de récupération terminée, l’IA se retrouve face à une contrainte : elle dispose d’un grand nombre de fragments d’information (les chunks), mais ne peut en exploiter qu’une partie.
C’est ici qu’intervient le re-ranking, une étape de sélection fine qui permet de distinguer les contenus simplement récupérés de ceux réellement utilisables pour générer la réponse.
1. Pertinence du chunk
Comme vous l’avez compris, l’IA récupère des “fragments” (chunks) de contenus qu’elle cherche ensuite à évaluer pour déterminer leur pertinence par rapport à la sous-requête.
Un bon chunk doit être compréhensible et utile de manière autonome. Si sa compréhension dépend fortement du contexte (paragraphes avant/après), sa valeur diminue.
Cette évaluation repose notamment sur des modèles dits cross-encoders, qui analysent simultanément la requête et le fragment pour juger leur correspondance.
On ne parle plus ici uniquement de proximité sémantique entre deux vecteurs, mais bien d’une capacité d’inférence logique : ce fragment permet-il, à lui seul, de répondre correctement à la question posée ?
2. Densité informationnelle
Le système cherche ensuite à maximiser la valeur informationnelle de chaque fragment, on parle alors de densité informationnelle (ou sémantique).
Autrement dit, il privilégie les contenus :
- directs ;
- concrets ;
- riches en informations utiles.
Un extrait qui délivre plusieurs éléments actionnables en quelques lignes sera préféré à un contenu plus long mais dilué.
L’objectif est clair : maximiser le signal, minimiser le bruit..
3. Autorité et convergence
La pertinence ne suffit pas : l’IA applique également un filtre de confiance.
Elle évalue :
- la crédibilité de la source ;
- l’expertise de l’auteur ;
- et plus largement la fiabilité de l’entité éditrice.
On retrouve ici une logique proche du EEAT en SEO, mais appliquée à un niveau plus fin, celui du fragment.
Au-delà de l’autorité individuelle, le système analyse également la convergence des informations.
Lorsqu’un même élément est confirmé par plusieurs sources indépendantes, sa probabilité d’être retenu augmente.
On peut rapprocher ce mécanisme de la notion de corroboration en information retrieval : une information est d’autant plus fiable qu’elle est supportée par plusieurs sources distinctes et cohérentes.
Cette logique s’inscrit dans des approches de type evidence aggregation ou consensus scoring, où le système ne cherche pas une vérité unique, mais une information statistiquement robuste à travers plusieurs signaux convergents.
À l’inverse, une information isolée devra être portée par une source particulièrement crédible pour être sélectionnée.
4. Fraîcheur du contenu
Enfin, la temporalité peut jouer un rôle déterminant selon la requête.
Pour certains sujets (prix, réglementation, actualité), les contenus récents sont privilégiés. Cela suppose que les fragments soient correctement associés à des métadonnées temporelles.
À l’inverse, pour des sujets plus stables (ex : tourisme, concepts généraux), ce critère devient secondaire.
5. Le goulot d'étranglement : Le passage au "Top-K"
Une fois ces scores de pertinence, de densité, d'autorité et de fraîcheur attribués, le système doit opérer un arbitrage final. Il ne peut pas envoyer cinquante fragments au modèle de langage pour rédiger la réponse ; cela saturerait sa "fenêtre de contexte" et exploserait les coûts de calcul.
C'est ici que l'entonnoir se resserre sur le Top-K : une sélection ultra-restreinte des 3 à 7 meilleurs fragments. Ce choix est dicté par un impératif de diversité informationnelle. L'IA ne veut pas trois sources qui disent la même chose, même si elles sont excellentes. Elle va chercher à "remplir les cases" (nos fameux slots de l'étape 1) : une source pour l'itinéraire, une pour le budget, une pour le conseil inédit.
Pour figurer dans ce peloton de tête, votre contenu doit donc être mathématiquement indispensable : soit parce qu'il est le plus crédible sur un sujet consensuel, soit parce qu'il est le seul à apporter une précision unique que les autres ont négligée.
Conclusion : Devenez la brique élémentaire du puzzle
Comprendre le Query Fan Out, c'est accepter que l'ère du contenu "global" est terminée. Dans ce nouveau paradigme, vous ne rédigez plus pour un lecteur qui parcourt une page de haut en bas, mais pour un agent qui va "découper" votre expertise pour en faire une brique de sa propre réponse.
Le succès en GEO (Generative Engine Optimization) repose sur un équilibre subtil :
- anticiper l'explosion : Identifier les intentions implicites derrière chaque requête ;
- respecter la parité multimodale : Offrir l'information sous le format (tableau, liste, vidéo) que l'IA a déjà projetée ;
- maximiser la densité du fragment : Créer des unités d'information auto-suffisantes, denses et fraîches pour survivre au re-ranking.
Le SEO consistait à être "en haut de la pile". Le GEO consiste à être la pièce de puzzle dont l'IA ne peut pas se passer pour construire sa vérité. À vous désormais de structurer vos contenus non plus seulement pour être lus, mais pour être impérativement récupérés.
Newsletter
Les actus SEO & GEO chaque mois
Aucun spam. Les derniers insights directement dans votre boîte mail.
Questions fréquentes
Qu’est-ce que le Query Fan-Out en GEO ?
Le Query Fan-Out désigne le processus par lequel une IA transforme une requête unique en plusieurs sous-requêtes. L’objectif est de couvrir l’ensemble des intentions implicites afin de produire une réponse complète et pertinente.
Quelle différence entre SEO classique et recherche générative ?
Le SEO classique classe des pages selon leur pertinence pour une requête donnée. La recherche générative, elle, construit une réponse en combinant plusieurs sources, en fonction de leur probabilité de satisfaire l’utilisateur dans un contexte donné.
Pourquoi structurer son contenu est devenu essentiel en GEO ?
Les IA ne lisent pas une page comme un humain : elles extraient des fragments. Un contenu structuré (titres, listes, blocs clairs) est plus facilement compris, récupéré et réutilisé dans une réponse générée.






Partagez votre avis, vos questions, vos recommandations ci-dessous