Comment corriger l’erreur “explorée, actuellement non indexée” dans la Google Search Console ?

Ce qu'il faut retenir
EN RÉSUMÉ
La priorité est d’abord de comprendre pourquoi Google a exploré une page sans l’indexer. Cette situation peut être un faux-positif, mais elle révèle souvent un contenu trop faible, trop proche de l’existant, mal maillé ou techniquement difficile à interpréter. Le guide propose une méthode de diagnostic : vérifier l’indexation réelle, analyser les SERP, améliorer la qualité et l’originalité du contenu, renforcer le maillage interne et contrôler l’architecture technique. Il rappelle aussi que certaines URLs peuvent légitimement rester non indexées, comme les flux RSS, pages paginées, produits expirés ou contenus privés.
“Explorée, actuellement non indexée” signifie que Google a crawlé la page, mais refuse pour l’instant de l’indexer.
Les causes fréquentes concernent la qualité, l’unicité du contenu, le maillage interne, l’architecture ou un problème technique.
Le diagnostic commence par vérifier le faux-positif, puis comparer la page aux résultats déjà présents dans Google.
Certaines URLs non indexées sont normales : flux RSS, pagination, produits expirés, pages redirigées ou contenus privés.
1h de coaching avec un expert
Réserver mon coaching
DÉBUT DE L'ARTICLE
L'erreur "Explorée, actuellement non indexée" signifie qu'une ou plusieurs pages de votre site web ne sont pas indexées sur Google. Cette erreur peut être la conséquence de plusieurs facteurs : un faux-positif, une qualité de contenu faible, un problème d'unicité du contenu, voire même un soucis technique. Je vous explique tout dans cet article.
Qu'est-ce que l'erreur "explorée, actuellement non indexée" dans la Google Search Console ?
L’indexation est la première étape pour que votre contenu soit enfin accessible sur les moteurs de recherche comme Google. Mais après plusieurs jours, votre contenu n’est toujours pas indexé. C’est alors que vous vous rendez dans le rapport d’indexation de la Google Search Console et que vous retrouvez votre nouvelle page dans la catégorie “Explorée, actuellement non indexée”

Mais que signifie donc cette erreur qui peut affecter jusqu’à une part non négligeable des URLs de votre domaine ? Un rapide coup d’œil au centre d’aide de Google ne nous apportera malheureusement pas beaucoup d’informations complémentaires puisque celui-ci explique l’erreur explorée, actuellement non indexée comme suit :
La page a été explorée par Google, mais pas indexée. Elle sera peut-être indexée à l'avenir ; il n'est pas nécessaire de renvoyer cette URL pour l'exploration.
Elle sera “peut-être”... Alors que vous aviez préparé votre plus beau brief de rédaction seo pour votre meilleur rédacteur spécialisé, Google vous répond simplement “peut-être”.
Voilà qu’en plus d’être frustrant, cela s’avère être rageant.
Rappelons que l’indexation d’une page se fait en trois étapes (grossièrement schématisé) :
- La découverte ;
- L’exploration (que l’on appelle aussi crawl) ;
- L’indexation.
Cette erreur indique dans l’URL a bien été découverte, puis que le Googlebot a chargé cette page pour en découvrir le contenu. Néanmoins, il n’est pas allé jusqu’à l’étape de l’indexer.
Pas de panique, chez We Growth nous résolvons ce problème en regardant quatre dimensions :
- Les autres résultats dans les SERPs ;
- La qualité du contenu ;
- L’unicité du contenu ;
- Votre maillage interne ;
- La dimension technique.
Comment résoudre l’erreur “explorée, actuellement non indexée” ?
Comme vous avez pu le voir ci-dessous, Google n’est pas très loquace dans la description de cette erreur. Mais il y a plusieurs aspects qui peuvent vous permettre de corriger l’erreur ‘explorée non indexée” de la Google Search Console.
Vérifier que ce n’est pas un faux-positif
Cela peut arriver que votre URL apparaisse dans le rapport comme page “explorée, actuellement non indexée” et pourtant qu’elle soit indexée.
Le plus simple reste d’utiliser la commande “site:” suivie de l’URL de votre site pour vérifier si celle-ci apparaît dans l’index, comme pour l’exemple ci-dessous :
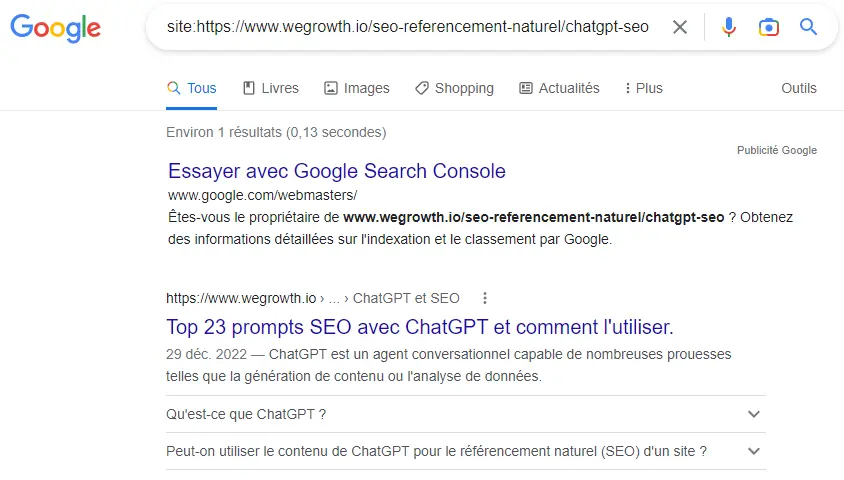
On voit bien dans l’impression d’écran ci-dessus, que notre article dédié aux prompts ChatGPT en SEO est bien indexé. Nous sommes dans le cas d’un faux-positif.
Si néanmoins, l’URL est bien absente de l’index de google, alors continuez de lire cet article.
Différenciation de votre contenu par rapport au Top 10
Gary Ilyes de Google, a confirmé en Mai à la SERP Conf 2024 en Bulgarie, que si votre contenu était trop similaire aux contenus déjà présents dans les SERPs et que votre domaine envoyait des signaux moins puissants que la concurrence, cela pouvait expliquer que votre page soit explorée mais considérée comme inutile à indexer.
It can be a bunch of things, dupe elimination is one of those things, where we crawl the page and then we decide to not index it because there’s already a version of that or an extremely similar version of that content available in our index and it has better signals.
Vous pouvez retrouver cet extrait à la 9ème minute du passage de Gary Ilyes sur Youtube.
En d’autres termes : est-ce que votre contenu se différencie de ce qui existe déjà dans l’index de Google ? Si votre contenu est trop similaire à ce qui est déjà indexé et qu’en plus votre domaine est moins puissant que les domaines déjà présents, il est probable que Google ne vous indexe pas. D’où l’importance de bien analyser le contenu déjà présent dans les résultats de recherche avant d’écrire afin de vous assurer que vous pouvez apporter une certaine valeur ajoutée que les autres contenus n’offrent pas.
Pour cela, je vous invite à consulter les 5 à 10 premiers résultats sur la requête que vous ciblez pour vous faire une idée précise de ce qui existe déjà et ainsi identifier de potentiels axes de différenciation.
Améliorez votre contenu
Rappelons-nous que Google a un objectif : servir des pages avec du contenu de haute qualité qui répond à l’intention de l’utilisateur même si cette intention seo n’est d'ailleurs pas explicite.
En parallèle, souvenons-nous que Google est limité en ressources, que ce soit sa capacité de stockage, ou sa puissance de calcul. Non pas que Google ne soit pas à la pointe sur ces sujets techniques, mais avec des trillions de pages sur le web, il est nécessaire de trier et prioriser (même pour un robot).
Vous comprendrez alors que Google ne peut pas indexer toutes les pages du World wide web.
Ainsi, si votre page n’est pas indexée, cela s’explique probablement par une qualité du contenu qui ne correspond pas aux standards attendus par Google.
Prenez alors un peu de recul sur votre contenu et posez-vous la question suivante :
- Mon contenu est-il aligné avec les besoins de mon persona ?
- Mon contenu répond-t-il à une intention de recherche de mon persona ?
- Mon contenu fournit-il un ensemble de réponses authentiques, uniques, et claires ?
Je ne peux que vous conseiller de relire votre article à la lumière des nouvelles directives EEAT de Google, directives finies à ses équipes en charge de l’évaluation manuelle (comprendre par un humain et non un robot) du contenu, explicitant les quatre piliers d’un bon contenu :
- Experience et authenticité de l’auteur ;
- Expertise de l’auteur ;
- Authoritativeness (autorité / légitimité) de l’auteur et du domaine ;
- Trust (confiance) accordée au domaine.
Pour en savoir plus sur le Google EEAT, vous pouvez consulter notre article Qu’est-ce que l'EEAT de Google et en quoi est-ce important pour votre SEO ?
Et pour vous orienter, Google partage dans cet article une liste de questions à laquelle se soumettre pour évaluer son contenu dans une démarche de qualité.
Votre contenu fournit-il des informations, des rapports ou des travaux de recherche ou d'analyse véritablement originaux ?
Offre-t-il une description substantielle ou exhaustive du sujet ?
Fournit-il des informations réellement utiles et intéressantes ?
Si votre contenu s'appuie sur d'autres sources, l'avez-vous simplement recopié ou reformulé, ou y avez-vous apporté de la valeur ajoutée et une touche d'originalité ?
Le titre résume-t-il clairement le contenu de la page ?
Le titre de la page utilise-t-il un langage approprié et non offensant ?
Est-ce le genre de page que vous aimeriez ajouter à vos favoris, partager avec un ami ou recommander ?
Ce contenu pourrait-il apparaître dans un magazine, une encyclopédie ou un livre en version papier ?
User Generated Content et indexation SEO
Voilà un sujet que l’on ne rencontre pas souvent.
Imaginons que vous ayez un forum, ou un site web sur lequel chaque utilisateur peut créer une page dédiée pour son événement, très souvent ces pages vont être pauvres en contenu.
Sur un forum par exemple, lorsqu’un utilisateur ouvre un nouveau sujet, si Google crawle page dédiée au moment où il n'y a pas ou peu de réponses, cette page pourra être considérée comme de faible qualité par le moteur de recherche.
Pareil pour un service de billetterie en ligne ou d’événements, où chacun pourrait créer sa page dédiée. Vous, en tant qu’éditeur de site, vous offririez à vos utilisateurs des pages types avec des champs à remplir. Mais si l’utilisateur décide de ne pas s’épancher, il se peut qu’au final ces pages soient non seulement peu qualitatives, mais aussi des near duplicates.
Il est donc nécessaire de trouver le savant équilibre entre forcer vos utilisateurs à créer un contenu plus riche sans que cela ne devienne une barrière à l’utilisation de votre plateforme. Prenons deux exemples : Quora et Stack Overflow.
Ces deux sites sont des forums, mais chacun a une manière différente de gérer des contenus de faible qualité :
Quora, par exemple, bloque via le fichier robots.txt chaque URL de sujet qui n’a pas de réponses apportées par la communauté. Ainsi, si vous créez un nouveau sujet sur le site, vous verrez votre URL précédée d’un sous-dossier “/unanswered/”. Un rapide coup d’œil à leur fichier robots.txt vous montrera que l’exploration de l’ensemble des pages de ce sous-dossier est bloquée.
Stack Overflow a une approche moins “technique” dirons-nous. Lorsque l’internaute tente d'ouvrir un sujet de discussion - et donc une nouvelle page - le moteur de recherche interne va automatiquement chercher si le sujet n’a pas déjà été traité sur une autre page. Si c’est le cas, la plateforme va inciter l’utilisateur à se rendre sur l’URL avec la question déjà traitée plutôt que créer une nouvelle page.
Unicité du contenu et duplicate
Votre objectif est bien évidemment de fournir du contenu unique et de qualité à vos utilisateurs par l’intermédiaire des moteurs de recherche.
Mais que se passe-t-il si lors de son crawl, le Googlebot remarque que plusieurs de vos pages (d’un même site web) ont un contenu assez similaire ? Et bien il peut décider de n’en indexer qu’une seule. C’est notamment ce qui peut se passer pour du contenu UGC ou pour des sites e-commerce.
Si vous avez de nombreuses pages très fortement similaires (variation de caractéristiques pour un seul produit type couleur ou contenance), vous pouvez aider Google à déterminer la bonne page à indexer en utilisant :
- La balise canonique qui pointe vers l’URL “maître” ;
- Incluant la version canonique dans votre sitemap XML ;
- Vérifiez votre maillage interne pour que la page la plus importante ait plus de liens entrants que les pages de “variation”.
Cela ne fera pas disparaître l’entièreté des pages en “explorée actuellement non indexée”, mais cela permettra d’avoir les pages principales indexées.
Et rappelons-nous d’ailleurs que Google accorde beaucoup d’importance à l’originalité du contenu.
Avoir une architecture de site propre et lisible
On ne le répètera jamais assez mais l’architecture de votre site est essentielle. Cela permet aux moteurs de recherche de comprendre la relation entre vos pages et donc quelles sont les pages les plus importantes.
Encore une fois, dans la liste de pages avec l’erreur “explorée actuellement non indexée” de la Google Search Console, si une page est importante, vérifiez que celle-ci est :
- Accessible en maximum 3 clics depuis la page d’accueil ;
- Que celle-ci est bien inclue dans votre sitemap XML ;
- Que des liens internes pointent vers elle et donc que cette page n’est pas orpheline.
Le type de pages que l’on retrouve le plus souvent avec l’erreur “explorée actuellement non indexée”
Quand vous analysez le rapport d’indexation de la Google Search Console, et particulièrement la liste d’URL concernée par le problème “explorée actuellement non indexée”, vous pouvez trouver certaines URLs qui ne nécessitent pas nécessairement d’intervention de votre part.
Pages de flux RSS :
Si votre site internet utilise un flux RSS, il se peut que vous retrouviez certaines URL propres à vos catégories dans la liste de pages “explorée actuellement non indexée”. Ces URL ne sont souvent que du code XML, donc il est normal que Google ne souhaite pas les indexer.
URLs paginée :
Notamment sur des sites d’informations ou des e-commerces, vous pouvez retrouver des URLs paginées dans le rapport d’erreur.
N’y touchez pas, car Google utilise ces pages pour accéder aux autres contenus derrière. Il se peut néanmoins qu’il ne souhaite pas les indexer car elles ne présentent que peu de valeur en elles-mêmes. Vérifiez seulement que :
- Elles contiennent une balise canonique vers elles-mêmes ;
- Elles ne possèdent aucune balise head en nofollow ;
- Et qu’aucun des liens internes ne soit aussi en nofollow.
Laissez donc bien Google les explorer puisqu’elles permettent aux robots de découvrir les autres pages.
Pages de produits expirés :
Si vous êtes un e-commerce, Google peut décider de désindexer un produit n’est plus disponible en stock afin de ne pas pénaliser l’expérience des internautes qui chercheraient un produit sur le moteur de recherche. Donc vérifiez bien la disponibilité de vos stocks pour vous assurer que vous ne ratez pas une opportunité.
Et attention, car Google vérifie aussi les données structurées et le champ “availability”.
Pages redirigées :
Imaginons que vous aviez une page A et que pour certaines raisons vous avez créé une page B et décidé d’implémenter une redirection 301 de la page A vers la page B.
Il se peut que vous retrouviez la page B dans la liste des pages web avec le problème “explorée, actuellement non indexée”. Cela s'explique par le fait que la page A est sûrement encore indexée sur Google.
Dans ce cas, un peu de patience suffira. Néanmoins, si l’erreur persiste ou est présente en grand nombre, c’est le moment de nous appeler.
Pages “privée” / pages “parasites” :
Parfois, il se peut que Google commence à indexer les tickets de votre outil de support client, les tickets de votre backlog Jira par exemple, ou des listes d’offres d’emplois sur un sous-domaine. Bref, des pages que vous ne souhaitiez pas que Google trouve, et qui consomment une grande partie de votre crawl budget même si elles ne sont pas indexées puisque dans le rapport “explorées non indexées”.
Dans ce cas, deux choses à faire :
- Trouver les liens internes qui relient votre domaine avec ces sous-domaines / ces outils. Pour ce faire, vous pouvez lancer un crawl depuis votre page d’accueil et trouver les liens internes que vous pourrez ensuite supprimer.
- Pour que cela ne se reproduise pas, vous pouvez interdire l’exploration à partir du fichier robots.txt. Si trop de pages sont déjà indexées, il faudra déployer la balise noindex sur l’ensemble de ces pages ou les protéger via un mot de passe pour les rendre inaccessibles au Googlebot.
Surveillez votre couverture d’indexation
Plus largement, nous vous conseillons de surveiller le niveau d’indexation (la couverture) de vos pages très régulièrement en utilisant la Google Search Console. Au moins une fois par semaine.
Il se peut en effet que vous trouviez des pages catégorisées avec le problème “explorée, actuellement non indexée” alors que ces pages étaient indexées auparavant. Cela peut arriver pour plusieurs raisons :
- Une autre de vos pages a cannibalisé la page désindexée ;
- Google a déployé une mise à jour de son algorithme qui pénalise in fine votre url ;
- Votre page connaît des problèmes techniques et son contenu n’est plus perçu aussi qualitatif qu’avant (ex : problème de rendering sur un site en Javascript).
Restez donc alerte sur ce type de problèmes qui peuvent survenir même post-indexation.
Quelle différence entre “explorée actuellement non indexée” et “découverte actuellement non indexée” ?
Il ne faut pas confondre ces deux erreurs même si elles semblent assez similaires puisque dans les deux cas votre page n’est pas indexée et c’est pourtant ça le nerf de la guerre.
Dans le cas des pages présentant l’erreur “découverte actuellement non indexée”, l’URL est connue de Google mais elle n’a jamais été explorée. Vous pouvez d’ailleurs vous référer à notre article dédié Comment corriger l’erreur “détectée, actuellement non indexée” dans la Google Search Console ?
Ainsi, la différence principale entre les deux se fait sur la partie exploration. Concernant le problème “explorée, actuellement non indexée”, la page a été crawl par le Googlebot, alors que ce n’est pas le cas concernant les pages web avec le problème “détectée, actuellement non indexée”.
Cependant, les raisons derrière ce problème peuvent être les mêmes : une faible qualité de contenu et/ou un problème de maillage interne entre vos pages. La différence fondamentale entre ces deux problèmes est que l’erreur peut être technique concernant “détectée, actuellement non indexée”. Mais nous vous conseillons de consulter notre article dédié sur le sujet.
Ce qu’il faut retenir
En résumé, l’erreur “explorée actuellement non indexée” concerne bien souvent des pages web avec un contenu de qualité médiocre. Si cependant vous ne doutez pas de la qualité de votre contenu, vérifiez votre maillage interne et la structure de votre site web.
Très rapidement, voici comment faciliter l’indexation d’une page qui aurait le problème “explorée, actuellement non indexée” :
- Ajouter du contenu unique (non dupliqué), et qui correspond à l’intention de votre persona. Une fois votre page enrichie, refaites une demande d’indexation via la Google Search Console ;
- Reprenez l’architecture de votre site et vérifiez que votre page est bien reliée à votre site internet et est rapidement accessible depuis votre page d’accueil ;
- Reprenez votre stratégie d’indexation afin de prioriser les pages génératrices de leads ou de ventes et désindexer des pages à faible valeur ajoutée (ex : pages de variation d’un produit e-commerce, des pages UGC, etc.).
Et si les problèmes persistent, il peut être nécessaire de contacter notre agence SEO technique pour aider à améliorer l’indexation de votre site.
Newsletter
Les actus SEO & GEO chaque mois
Aucun spam. Les derniers insights directement dans votre boîte mail.
Questions fréquentes
Que signifie l'erreur "explorée, actuellement non indexée" dans la Google Search Console ?
Cette erreur signifie que le Googlebot a découvert puis exploré votre URL, mais n'a pas souhaité l'indexer. Cela ne signifie pas qu'elle ne le sera pas dans un futur proche, mais rien n'est moins sûr. En général, cela peut être dû à (1) un contenu de faible qualité ; (2) du contenu dupliqué ou trop similaire ; (3) un mauvais maillage interne avec une architecture de site pas claire ; (4) un crawl budget insuffisant car brûlé sur des pages moins importantes que celles que vous souhaitez indexer.
Comment corriger l'erreur "explorée, actuellement non indexée" ?
Il y a plusieurs solutions potentielles pour la corriger : (1) améliorer le contenu de la page en adéquation avec l'intention utilisateur ; (2) vérifier que votre contenu est unique et pas dupliqué ; (3) vérifier le maillage interne et que votre page est rapidement accessible depuis la page d'accueil et donc pas orpheline ; (4) vérifier que votre crawl budget n'est pas consommé bêtement sur des pages sans importance.
Quelle différence entre "détectée actuellement non indexée" et "explorée actuellement non indexée" ?
Bien que les deux problèmes semblent similaires et que les causes sont souvent les mêmes, à savoir qualité du contenu et maillage interne, concernant l'erreur "explorée actuellement non indexée" le Googlebot a pris la peine d'explorer votre page avant de prendre la décision qu'elle ne "méritait" pas d'être indexée. C'est donc souvent un sujet de qualité de contenu alors que la source du problème pourrait être technique concernant le problème "détectée actuellement non indexée".







Partagez votre avis, vos questions, vos recommandations ci-dessous