Comment corriger l’erreur “détectée, actuellement non indexée” dans la Google Search Console ?

Ce qu'il faut retenir
EN RÉSUMÉ
Le vrai enjeu du statut “détectée, actuellement non indexée” est de comprendre pourquoi Google ne juge pas une URL prioritaire à explorer. Le problème peut être ponctuel, mais il peut aussi révéler une faiblesse plus globale : contenus peu qualitatifs, pages dupliquées, mauvais maillage interne, sitemap imparfait, redirections inutiles, serveur lent ou site trop lourd. Le guide propose une méthode pour identifier les pages réellement prioritaires, améliorer leur valeur perçue, faciliter leur découverte par Google et mieux utiliser le crawl budget afin d’augmenter les chances d’indexation.
“Détectée, actuellement non indexée” signifie que Google connaît l’URL, mais ne l’a pas encore explorée.
Le problème peut venir de la qualité perçue du site, du contenu, du maillage interne ou du crawl budget.
Toutes les URLs concernées ne doivent pas forcément être corrigées, surtout si elles sont volontairement exclues.
Les solutions passent par un contenu plus utile, un sitemap propre, un bon maillage, moins de redirections et un site plus léger.
1h de coaching avec un expert
Réserver mon coaching
DÉBUT DE L'ARTICLE
Comprendre le statut “détectée actuellement non indexée”
Qu’est-ce qu’il peut être frustrant alors que l’on a travaillé proprement le contenu, l’arborescence et le maillage interne de notre site que de découvrir que nos pages ne sont pas indexées !
Avant de parler des différentes solutions pour réduire ce nombre, voire l’amener à zéro comme c’est le cas de notre site, il faut comprendre ce à quoi correspond cette erreur.
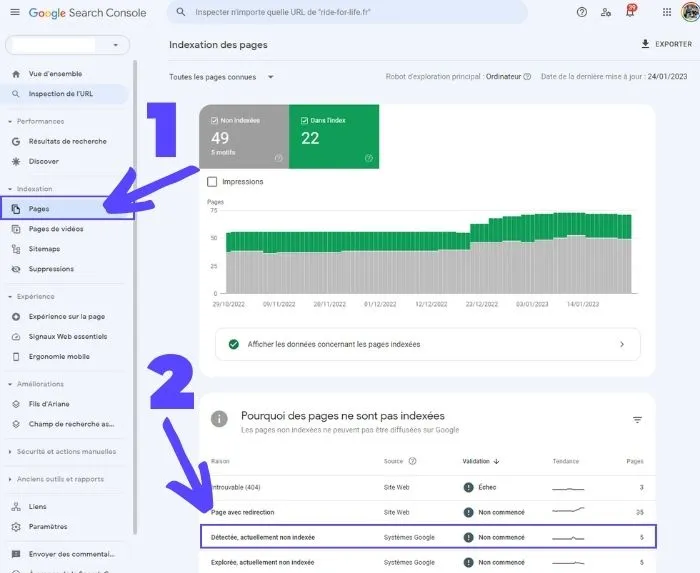
Rappelons-nous que le procédé d’indexation chez Google se déroule en 3 étapes :
- La découverte ;
- Le crawl (ce qu’on appelle aussi l’exploration) ;
- L’indexation.
Ainsi, quand votre page comporte le statut “détectée actuellement non indexée”, cela signifie que cette première a bien été découverte, mais que Google n’a pas jugé pertinent de l’explorer et de l’indexer sur le moment. Contrairement au problème "explorée, actuellement non indexée" qui concerne des pages découvertes ET explorées pour lesquelles Google ne souhaite pas les indexer (mais on vous en dit plus dans notre article dédié Comment corriger l’erreur “explorée, actuellement non indexée” dans la Google Search Console ? ).
Et une page non indexée est une page introuvable sur les moteurs de recherche et qui ne vous apportera donc pas de traffic et mettra en péril vos objectifs SEO.
Mais comment expliquer ce “problème” ? Google, dans sa documentation dédiée au Rapport sur l'indexation des pages décrit le statut “détectée, actuellement non indexée” comme ceci :
La page a été détectée par Google, mais n'a pas encore été explorée. En règle générale, cela signifie que Google voulait explorer l'URL, mais que l'exploration a été reportée, car votre site risquait d'être surchargé. C'est pourquoi la dernière date d'exploration ne figure pas dans le rapport.
Et effectivement, la date d’exploration ne figure pas dans le rapport de la Google Search Console pour certaines pages de ce site sous Wordpress.
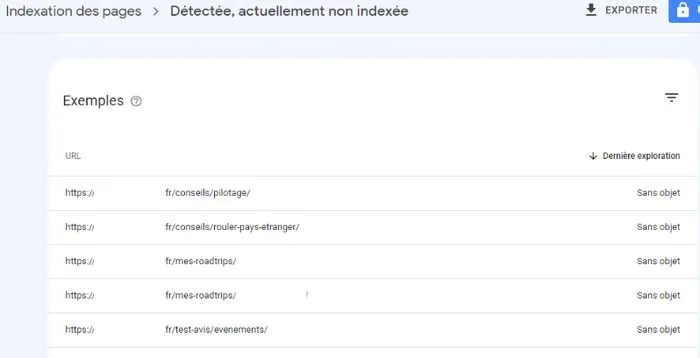
Ainsi, il est possible que le Googlebot revienne pour crawl votre URL en vue d’une potentielle indexation.
En pratique, cela peut effectivement arriver. Mais malheureusement, pour quiconque a déjà mesuré, vous vous apercevrez que ce crawl sur une URL détectée peut intervenir des semaines après la première détection (voire jamais).
De plus, il peut y avoir d’autres raisons qui expliquent que Google ne souhaite pas dédier des ressources à explorer vos pages.
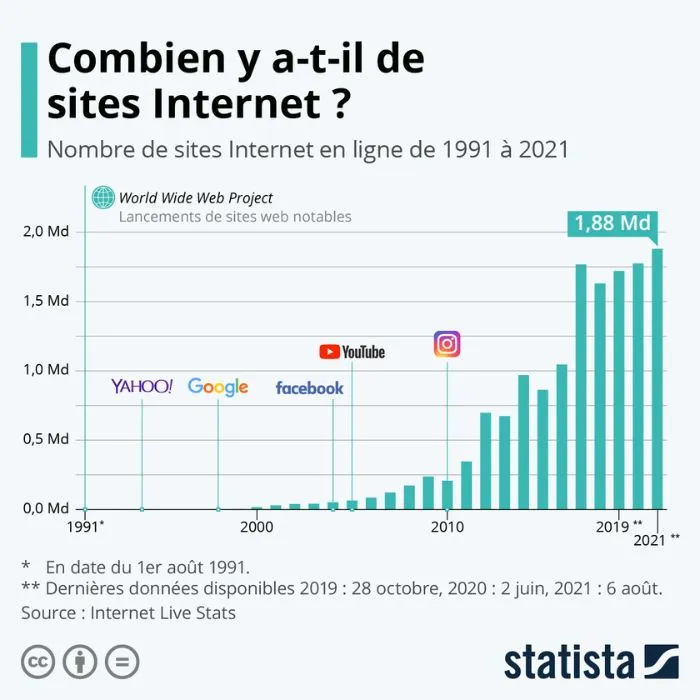
Après tout, dans une étude publiée par Statista, le Word Wide Web comptait 1,8 milliard de sites internet notables.
Alors comment s’assurer que Google considère votre page comme pertinente et “méritante” pour être indexée ?
Quand faut-il optimiser une page “détectée actuellement non indexée” ?
Bien évidemment, tout est une histoire de proportion et d’intention. Il n’est pas nécessaire de retravailler systématiquement vos pages qui ont le statut “Détectée, actuellement non indexée” à condition que :
- Le nombre de pages avec ce statut reste faible (inférieur à 10%) et qu’en général, elles finissent toujours par être indexées avec le temps ;
- Que les URLs des pages dans le rapport soient des URLs qui ne doivent justement pas être explorées ou indexées (par exemple, la page avec une canonical pointant vers une autre page, des pages avec des balises noindex, ou encore des contenus bloqués via le fichier robots.txt).
Si tout vous paraît normal, regardez quand même régulièrement ce rapport. Et si un jour, vous constatez dans le rapport “détectée actuellement non indexée” que :
- Le nombre d’URLs avec ce statut a augmenté ;
- Que des contenus importants ont le statut “détectée actuellement non indexée”.
Alors, il est important de retravailler vos pages prioritaires.
L’outil d’inspection de l’URL de la Google Search Console
Une fois le contenu des pages modifié, vous pouvez demander à Google une nouvelle visite du Googlebot en utilisant l’outil d’inspection de l’URL de la Search Console.
Pour se faire :
- Ouvrez la Google Search Console ;
- Cliquez sur “Inspection de l’URL” dans la barre de navigation à gauche ou dans la barre de recherche en haut ;
- Collez l’URL de la page modifiée et appuyer sur “Entrée” ;
- Cliquez enfin sur “Demander une indexation”.
Procéder de la sorte ne vous garantit pas l’indexation de votre page. Néanmoins, vous invitez le Googlebot à redécouvrir votre page et à la reconsidérer à la suite des changements que vous y avez apportés. Et si ces changements sont suffisants selon les standards du moteur de recherche, alors il y a fort à parier que votre contenu sera indexé prochainement.
8 solutions pour ne plus avoir de pages en “détectée, actuellement non indexée”
Solution #1 : vérifier le contenu
Comme vous vous en doutez, Google ne peut explorer les dizaines de milliards de pages existantes sur le web. Ainsi, les robots de Google vont prioriser les pages des domaines qui respectent certains standards de qualité.
En d’autres termes, si Google considère que le contenu habituellement publié sur votre domaine est de faible qualité, il est fort probable qu’il ne se presse pas pour une nouvelle URL que vous auriez publiée.
Vous l’aurez donc compris, le problème “détectée, actuellement non indexée” concerne une URL, mais l’origine du problème peut être la qualité perçue de votre site.
John Mueller, le grand gourou SEO de Google, le confirmait d’ailleurs à la 26ᵉ minute des Google SEO office-hours de décembre 2021.
Pour que votre contenu, et plus largement votre site web soit considéré “aux standards”, interrogez-vous sur ces 3 axes :
- L’accessibilité web (et je parle évidemment des normes d’accessibilité) ;
- La qualité du contenu ;
- Et l’unicité du contenu (dans le sens unique et non dupliqué).
Concernant l’accessibilité, nous n’allons pas nous étendre sur le sujet qui mériterait un article complet, mais je parle de taille de polices, de lisibilité du contenu, de choix des contrastes, présence de alt text pour les images, etc.
Au sujet de la qualité du contenu, le meilleur document pour comprendre comment Google évalue la qualité du contenu présent sur vos URLs est le Quality Rater Guidelines.
Si vous n’avez pas le temps de lire et analyser les 176 pages de ce document, on en a extrait le concept principal : l’EEAT de Google.
Anciennement connu sous le nom de EAT, mais depuis le 15 décembre 2022 sous le terme de EEAT, le concept englobe quatre dimensions :
- Experience de l’auteur sur son sujet (authenticité du contenu et partage d’expériences de vie réelle) ;
- Expertise de l’auteur sur le sujet ;
- Authoritativeness de l’auteur, du contenu et du domaine ;
- Trust que l’on pourrait voir comme la pertinence et l’honnêteté de l’auteur, du contenu et du domaine.
Si vous voulez aller plus loin sur ce sujet, nous vous invitons à consulter notre article Qu’est-ce que l'EEAT de Google et en quoi est-ce important pour votre SEO ?
Et enfin, l’unicité du contenu. Google ignorera les URLs qui paraissent comme dupliquées. Par exemple : plusieurs pages pour un même produit, mais de couleurs différentes. Ou encore des pages de services dédiées à différentes localisations et avec peu de contenu unique.
Si on prend un exemple concret, un site e-commerce avec un produit et plusieurs variations du produit (couleur, contenance, etc.), il est alors important d’utiliser les balises canoniques (canonicals). Ces balises permettent d’indiquer aux moteurs de recherche quelle version de la page est la version “maître” qui est donc indexée.
Imaginons 3 URLs :
- https://www.mon-ecommerce.fr/robe-rouge
- https://www.mon-ecommerce.fr/robe-rouge?taille=32
- https://www.mon-ecommerce.fr/robe-rouge?taille=34
- Etc.
Ces 3 pages ont le même contenu, car c’est le même produit. Mais elles existent indépendamment de chacune puisque le site est bâti ainsi. Il faudrait alors indiquer sur les pages “taille” que l’URL canonical est la page “maître” https://www.mon-ecommerce.fr/robe-rouge
Solution #2 : bloquer le crawl et l’indexation de vos contenus de faible qualité
Laisser Google parcourir l’intégralité de votre site internet peut parfois être une mauvaise idée. Comme nous l’expliquions, précédemment, Google a une quantité de ressources limitée dédiée à l’exploration.
Ainsi, si votre site comporte des pages de faible valeur, Google les explorera quand même et consommera l’ensemble des ressources d’exploration qu’il vous dédiait (nous parlons de crawl budget).
De plus, à la “lecture” de ces pages de faible qualité, Google pourrait considérer que l’ensemble des pages de votre domaine n’est pas au standard de qualité escompté et ainsiconsidérer que votre site ne requiert pas nécessairement plus d’exploration. Ainsi, sur le long terme, vous réduisez la capacité de votre domaine à être indexé.
Ce que vous pouvez faire dès maintenant, c’est recenser les pages de votre site qui sont de faible qualité et n’ont peu de valeur. Par exemple :
- Des pages anciennes qui traitent de sujets dépassés ;
- Des contenus dupliqués ;
- Les pages de résultats de votre moteur de recherche interne ;
- Les pages générées en utilisant des filtres (très présents sur les sites e-commerce) ;
- Les contenus auto-générés ;
- Les contenus UGC (User generated content).
Pour empêcher ces pages d’être explorées (crawl), vous devez les bloquer via l’utilisation de votre fichier robots.txt. Concernant l’indexation, vous devez utiliser la balise noindex dans le head de votre page.
Solution #3 : optimiser votre maillage interne
Google explore vos pages en suivant les liens interne à votre site. C’est de cette manière qu’il comprend l’architecture de votre site, et c’est aussi de cette manière que la “puissance SEO” est distribuée entre vos pages (ce qui fait écho au PageRank Sculpting).
Google considère aussi que plus une page a de liens internes, plus celle-ci est importante.
Donc, si cette nouvelle page est importante pour vous, assurez-vous que celle-ci n’est pas orpheline et que suffisamment de pages pointent vers votre nouveau contenu.
À la publication d’un nouveau contenu, pensez donc à :
- Vérifier qu’on peut accéder à votre nouvelle URL en quelques clics depuis votre homepage ;
- Que la page “mère” (par exemple la page catégorie) pointe vers sa page “fille” (votre nouvelle page produit) ;
- Que les pages traitant d’un sujet connexe ou complémentaire à votre nouvelle page pointent vers ce nouveau contenu ;
- Et alors que votre page n’est pas orpheline.
Et bien évidemment, vérifiez qu’aucun des liens internes ne soit en nofollow. En règle générale, aucun lien interne ne devrait être en nofollow.
Vous pouvez utiliser des outils comme Ahrefs ou ScreamingFrog pour trouver les pages orphelines ou les liens internes en nofollow.
Solution #4 : soumettre un sitemap propre et optimisé
Un sitemap est un fichier, souvent au format XML, avec l’ensemble des URLs vers les pages de votre site. C’est une manière de dire aux moteurs de recherche “voici l’ensemble de mes contenus, à toi de les découvrir”.
Il y a quelques règles à respecter lorsqu’on crée un sitemap :
- L’URL vers le sitemap doit être accessible constamment ;
- L’URL vers le sitemap doit être ajouté dans le robots.txt ;
- Les URLs présentent dans le sitemap doivent être accessibles avec un code réponse 200 (OK) ;
- Les URLs ne doivent pas avoir de balises noindex ;
- Et ces URLs doivent être les versions canonical.

Solution #5 : limiter les redirections
C’est une situation qui arrive plus fréquemment qu’on ne le pense. Mais il existe deux “cas” où les redirections peuvent être problématiques pour l’indexation :
- Les chaînes de redirection ;
- Les boucles de redirection.
Les chaînes de redirection, c’est quand vous vouliez rediriger le trafic d’une page A vers une page B, mais pour certaines raisons, vous finissez par avoir la page A qui redirige vers la page E qui elle-même redirige vers la page B.
Chaque fois que le robot va appeler une URL, il va consommer une “unité” de votre crawl budget. Ainsi, pour aller de A à B, il aura consommé 3 unités au lieu de 2. Et rappelons-nous que Google a des ressources limitées.
Pour information, sachez que Google peut suivre jusqu’à 10 redirections dans une seule chaîne. Jolie performance, mais vraiment pas utile ni conseillé.
Les boucles de redirection sont des boucles infinies où le navigateur et le robot vont “tourner en rond” et ne jamais atterrir sur une page en 200 présentant un contenu statique. Les boucles de redirection sont plus souvent le résultat d’erreurs humaines. Par exemple, page A redirige vers page B, mais pour une raison qui nous échappe, celle-ci redirige vers une page C qui elle-même redirige vers une page D qui elle-même redirige vers une page B. Vous l’aurez compris, c’est le serpent qui se mord la queue et résulte souvent en une erreur qui sera affichée dans la Google Search Console.
Solution #6 : avoir le bon hébergement
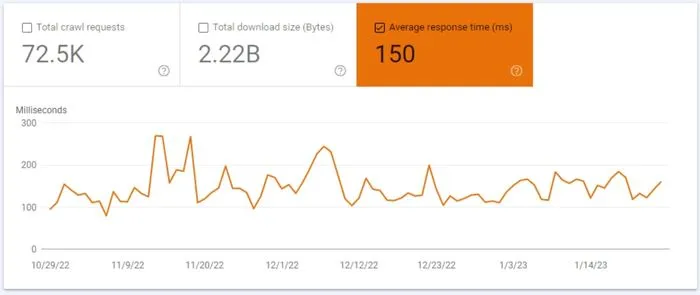
Si votre serveur connaît quelques ralentissements, qui peuvent être dus à diverses raisons (base de données remplies, problème de hardware, instance pas dimensionné par rapport au trafic sur votre site, et j’en passe), le Googlebot réduira les efforts qu’il déploie pour crawl votre site et donc le potentiel d’indexation de vos contenus.
Bien sûr, Google reviendra une autre fois en espérant que votre serveur sera alors en mesure de lui envoyer l’URL de la page et le contenu, mais tout cela arrivera plus tard. En conséquence, tout votre process d’indexation sera retardé.
Pour connaître le temps que prend votre serveur à répondre aux requêtes du Googlebot, suivez le procédé suivant :
- Ouvrir la Google Search Console ;
- Cliquez sur “Paramètres” dans la barre de navigation à gauche ;
- Sur la ligne “Statistiques sur l’exploration”, cliquez sur “Ouvrir le rapport” ;
- Et voilà !
Solution #7 : “alléger” votre site
Une page requérant généralement le téléchargement de nombreux composants (CSS, modules divers en Javascript par exemple), cela aura un impact négatif sur le crawl budget.
En effet, pour chaque composant additionnel que Google doit télécharger, il consomme une “unité” de ses ressources.
Ceci est assez courant pour les sites construits sur des frameworks en Javascript ou qui pour certaines raisons ont des fichiers CSS trop volumineux (on vous voit les pseudo agences web qui dupliquent des sites d’un projet à un autre et on se retrouve avec des fichiers CSS énormes…).
Pour en savoir plus sur le référencement naturel sur des sites en Javascript, consultez notre guide Javascript SEO : le guide complet pour un bon référencement naturel.
Solution #8 : vérifier vos backlinks
Rappelons que les liens entrants font partis des signaux analysés par Google pour déterminer la popularité et la qualité d’une page et donc si celle-ci mérite d’être explorée.
Ainsi, l’absence de backlinks vers votre nouveau contenu peut-être une des raisons qui n’encourage pas Google à indexer votre contenu.
En résumé
Les problèmes d’indexation d’URLs identifiée comme “détectée, actuellement non indexée” dans la Google Search Console sont souvent dues à ces 3 raisons :
- Un domaine de faible qualité ;
- Une page avec contenu de faible qualité ;
- Un mauvais maillage interne ;
- Des problèmes de crawl budget.
En général, pour les URLs concernées, vous devriez :
- Vérifier la qualité du contenu sur ces pages ;
- Vous assurer qu’il n’y a pas de contenus dupliqués ;
- Vous assurer que vos contenus sont bien reliés entre eux (maillage interne) ;
- Vérifier que ces pages ont de l’importance sinon les bloquer à l’exploration via le fichier robots.txt ;
- Optimiser votre crawl budget ;
- Vérifier les performances de votre hébergement.
Et si le problème persiste, n'hésitez pas à nous contacter.
Newsletter
Les actus SEO & GEO chaque mois
Aucun spam. Les derniers insights directement dans votre boîte mail.
Questions fréquentes
Que signifie l'erreur "détectée, actuellement non indexée" dans la Google Search Console ?
Cette erreur signifie que le Googlebot a découvert une URL, mais qu'il n'a pas jugé pertinent de l'explorer pour pouvoir ensuite l'indexer. Ainsi, Google sait que cette URL existe, mais il n'a pas encore priorisé son exploration pour pouvoir l'indexer. Si le problème persiste, cela peut signifier qu'il y a un problème plus profond avec la page voir le domaine entier.
A quoi est dû les pages détectées mais non indexées dans le rapport d'indexation ?
En général, cela peut être du à (1) un contenu de faible qualité, peu profond, court, voire dupliqué ; (2) un domaine jugé en-dessous des standards de Google en terme de qualité ; (3) un mauvais maillage interne ; (4) des problèmes de crawl budget.
Comment corriger l'erreur "détectée, actuellement non indexée" dans la Google Search Console ?
Il y a plusieurs pistes pour corriger cette erreur : (1) améliorer le contenu de votre page ; (2) vérifier qu'il n'y a pas de contenus dupliquées ; (3) vérifier que votre page n'est pas orpheline et plus largement la qualité de votre maillage interne ; (4) optimiser votre crawl budget ; (5) vérifier les performances techniques de votre hébergement.







Partagez votre avis, vos questions, vos recommandations ci-dessous